Project : RainMind 개발일지 - 10 [본격적인 서버 성능 모니터링을 위한 전처리]
Actuator, prometheus를 이용하여 스프링 앱의 CPU, 메모리 등을 모니터링한다.
해당 목표를 위해 거쳐야 할 절차들을 기록한다.
1) actuator, prometheus 의존성 추가(build.gradle.kts)
implementation("org.springframework.boot:spring-boot-starter-actuator")
implementation("io.micrometer:micrometer-registry-prometheus")
의존성을 추가한다.
2) application.yaml에 아래 내용을 추가한다.
해당 내용은 스프링 앱의 내부 상태를 어떻게, 그리고 어디까지 보여줄지 결정하는 내용이다.
management:
endpoints:
web:
exposure:
include: health,info,prometheus // health = 앱 살았는지 확인, info = 앱 전반 정보(버전 등), prometheus = prometheus가 수집할 데이터 노출용
endpoint:
health:
show-details: always
include에 있는 3가지 기능만 골라서 웹(HTTP)으로 오픈한다는 뜻이다. 아래 show-details에서는 애플리케이션의 세부 사항을 알려달라는 뜻이다.
3) prometheus 설정 파일을 만든다.
mkdir -p monitoring/prometheus
cd ./monitoring/prometheus
nano prometheus.yaml
이후 아래 내용을 입력한다.
global:
scrape_interval: 5s // 데이터 수집 주기 = 5초
scrape_configs: // prometheus가 감시할 대상
- job_name: "rainmind-app" // 우리 애플리케이션
metrics_path: "/actuator/prometheus" // spring boot가 남긴 데이터를 여기서 가져온다(spring 기본경로)
static_configs:
- targets: ["app:8080"]
- job_name: "cadvisor" // 컨테이너 CPU, memory 상황 수집
static_configs:
- targets: ["cadvisor:8080"]
- job_name: "redis-exporter" // redis 데이터 수집을 위해, 별도의 exporter를 거쳐야 함(9121)
static_configs:
- targets: ["redis_exporter:9121"]
4) docker-compose.ec2.yaml에 grafana, prometheus, redis-exporter, cadvisor 서비스를 사용하겠다고(이미지를 가져오겠다) 선언한다.
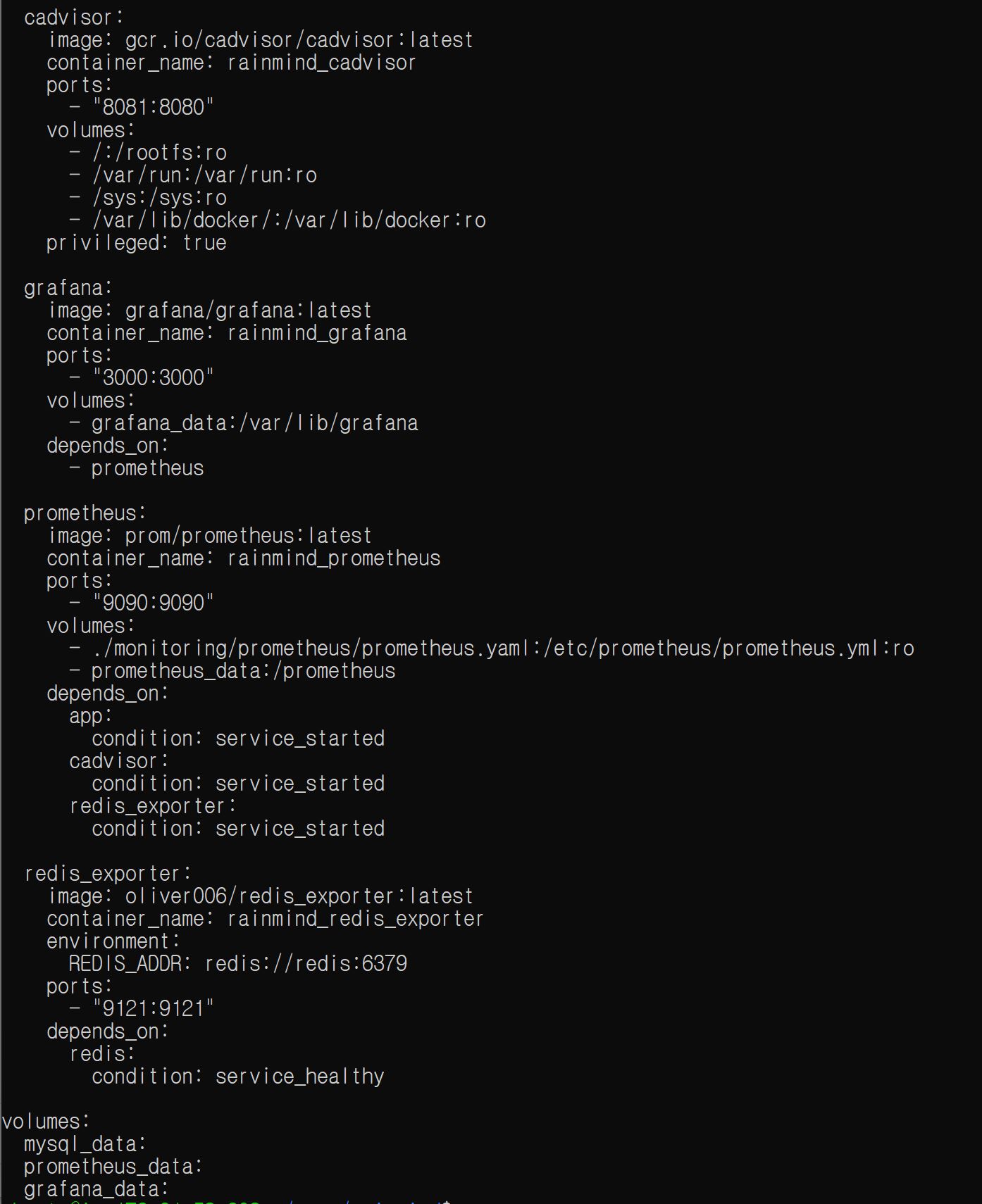
이후 docker compose -f docker-compose.ec2.yaml ps로 확인해보면 모든 서비스가 잘 로딩된 것을 확인할 수 있다.
5) 이제 IP:9090, IP:3000으로 들어가면 각각 prometheus, grafana 정상 접속이 가능함을 확인할 수 있다.
grafana에서 data source에 http://prometheus:9090을 등록해주고, dashboard를 아래처럼 만들어준다.
이제 아래에 PromQL을 입력(Prometheus Query Language)해야 한다. 예를 들어 초당 요청수를 보고 싶으면 sum(rate(http_server_requests_seconds_count{job=”rainmind-app”}[1m])) 이런식으로 작성하면 된다(이 부분은 인터넷 검색을 좀 더 해봐야 할 듯 하다).
현재 구조에서, 병목 원인을 추적하는 것이 목표이므로 조사해야 할 것은 아래와 같다.
- API 요청 대시보드: 초당 요청 수(서버가 요청 처리하는 능력), p95(속도), 로그인 p95 vs 스케줄 생성 p95(로그인 vs 스케줄 병목지점 파악)
- JVM, memory 대시보드: Heap 사용량, GC, CPU 사용량
- Redis 대시보드: redis 메모리 사용량 및 병목 지점
대략 이정도? 일단 사전 세팅은 전부 끝났으니, 직접 k6 스크립트로 테스트해볼 차례이다.
6) 클라이언트용 EC2를 하나 더 만든다.
로컬 컴퓨터는 내가 켜놓은 브라우저나 다른 앱들 때문에 성능 측정에 영향을 줄 수 있으므로, 같은 방식으로 EC2 인스턴스를 하나 새로 만든 후, EC2에 접속하여 k6를 설치하면 된다.
회원가입 요청은 서비스 가입 최초 1회만 발생하고, 이후에는 실제 서비스 사용에 영향을 많이 주지 않을 것이라 판단하여, 회원가입 성능까지 체크하지는 않을 것이다.
성능 테스트 시에는, 미리 200명의 유저들을 스크립트로 만들어둔 후, 해당 유저들에 대해 로그인 시도를 수행할 예정이다.
유저들 미리 만드는 스크립트는 아래와 같다.
import http from 'k6/http';
import { check, sleep } from 'k6';
import exec from 'k6/execution';
export const options = {
iterations: 200,
vus: 20
};
const BASE_URL = __ENV.BASE_URL;
export default function() {
const id = (__VU * 1000) + __ITER;
const nickname = `seed_${id}`;
const res = http.post(
`${BASE_URL}/v1/auth/user/register`,
JSON.stringify({
nickname,
password: 'password12345678',
region_name: 'Seoul'
}),
{
headers: {
'Content-Type': 'application/json'
}
}
);
console.log(`VU: ${__VU}, ITER: ${__ITER}, Nickname: ${nickname}, Status: ${res.status}`);
check(res, {
'register, or duplicate': (r) => r.status == 201 || r.status == 409
});
sleep(0.1);
}
1번부터 200번 유저들, 비밀번호/지역은 반드시 고정으로 하여 테스트를 단순화한다.
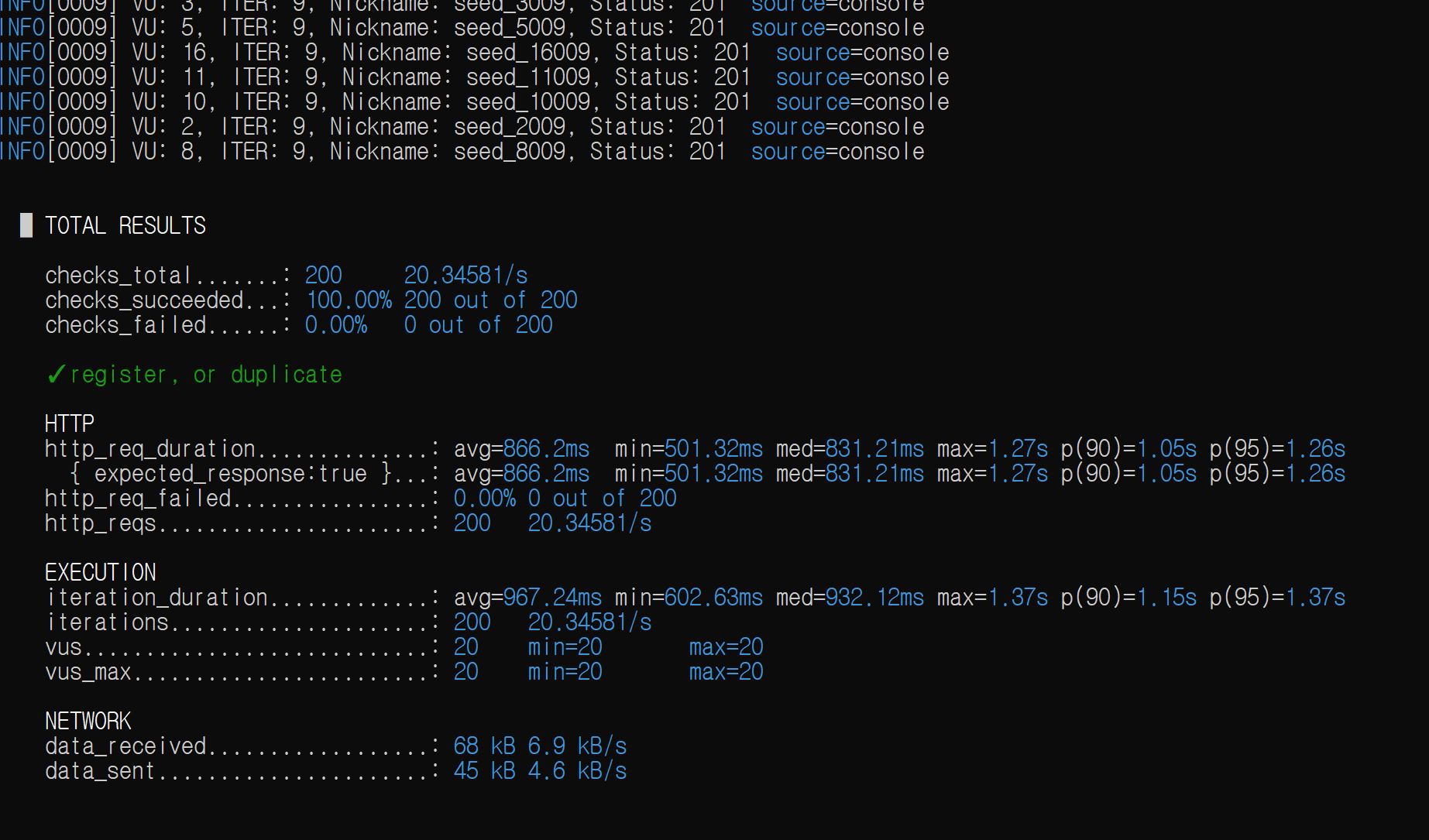
정확성을 위해 private IP(서버의)를 사용하여, k6 run -e BASE_URL=(주소) (스크립트.js)를 실행하여 결과를 받는다.
(사실 처음에 public IP로 했다가, 계속 설정 오류로 인한 i/o timeout이 나서 갈아탔다. 나중에 알아보니 AWS에서 보안그룹을 원본으로 참조하면 private IP만 허용해준다는 것이었다…)
이후 users 테이블에서 UNIQUE 제약을 건 줄 알았다가 안걸었던 것을 파악하고 고치는 이슈를 해결하고 나니, select * from users; 했을때 200이 딱 예쁘게 찍혀 나왔다.
이제 다음 게시글에서 최적화에 관해 수행하는 내용들을 기록해보고자 한다.