Project : RainMind 개발일지 - 11 [1번째 최적화 수행 기록]
본 글을 최적화 수행 기록(수치화 포함)에 관한 글이다.
수치적 요약 및 스크립트/사용한 PromQL 쿼리, 정제된 데이터는 다음 포스팅에 기록할 예정이다.
1) 회원가입 기능
유저 100명이, 3분동안 계속 회원가입 로직을 수행할 때를 모니터링해서 병목 지점이 있는지 찾고자 했다.
우선 그냥 돌렸을때이다.
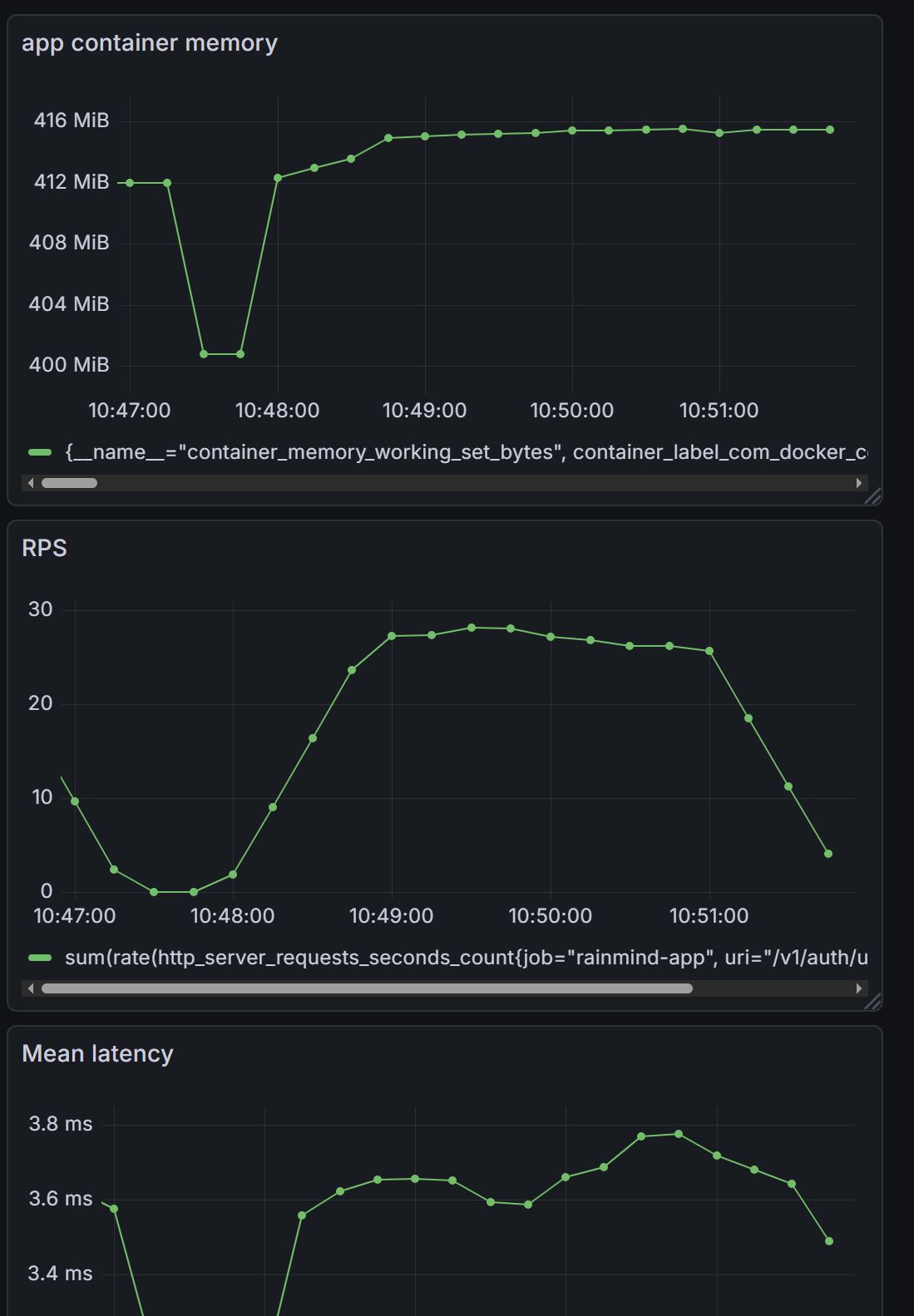 ??? 응답시간이 k6 EC2에서는 거의 4초가 걸린다(쿼리 = 1000 *
(
rate(http_server_requests_seconds_sum{job=”rainmind-app”, uri=”/v1/auth/user/register”}[1m])
/
rate(http_server_requests_seconds_count{job=”rainmind-app”, uri=”/v1/auth/user/register”}[1m])
)).
??? 응답시간이 k6 EC2에서는 거의 4초가 걸린다(쿼리 = 1000 *
(
rate(http_server_requests_seconds_sum{job=”rainmind-app”, uri=”/v1/auth/user/register”}[1m])
/
rate(http_server_requests_seconds_count{job=”rainmind-app”, uri=”/v1/auth/user/register”}[1m])
)).
output json을 뜯어보자.
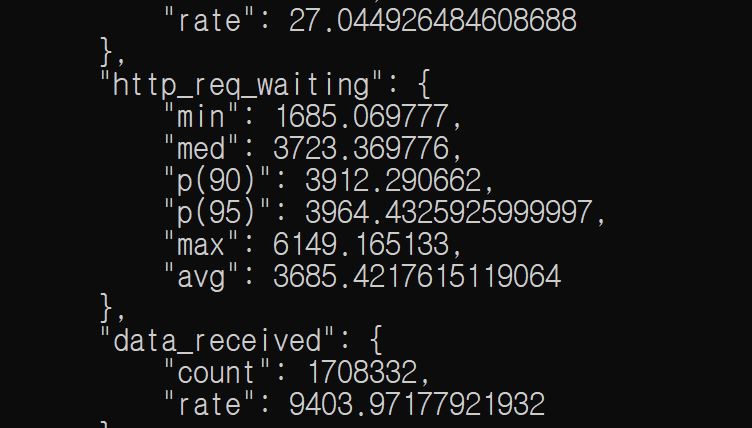
찾았다.
즉 회원가입 API에서 무거운 연산을 수행하기 때문에, 다른 요청들이 기다리는 시간이 거의 대부분이었던 것이다.
혹시나 DB 커넥션 풀(Hikari 기본 = 10) 때문인지 궁금하여, application.yaml에 기본 커넥션 풀 사이즈를 5배 늘여서 해보았지만
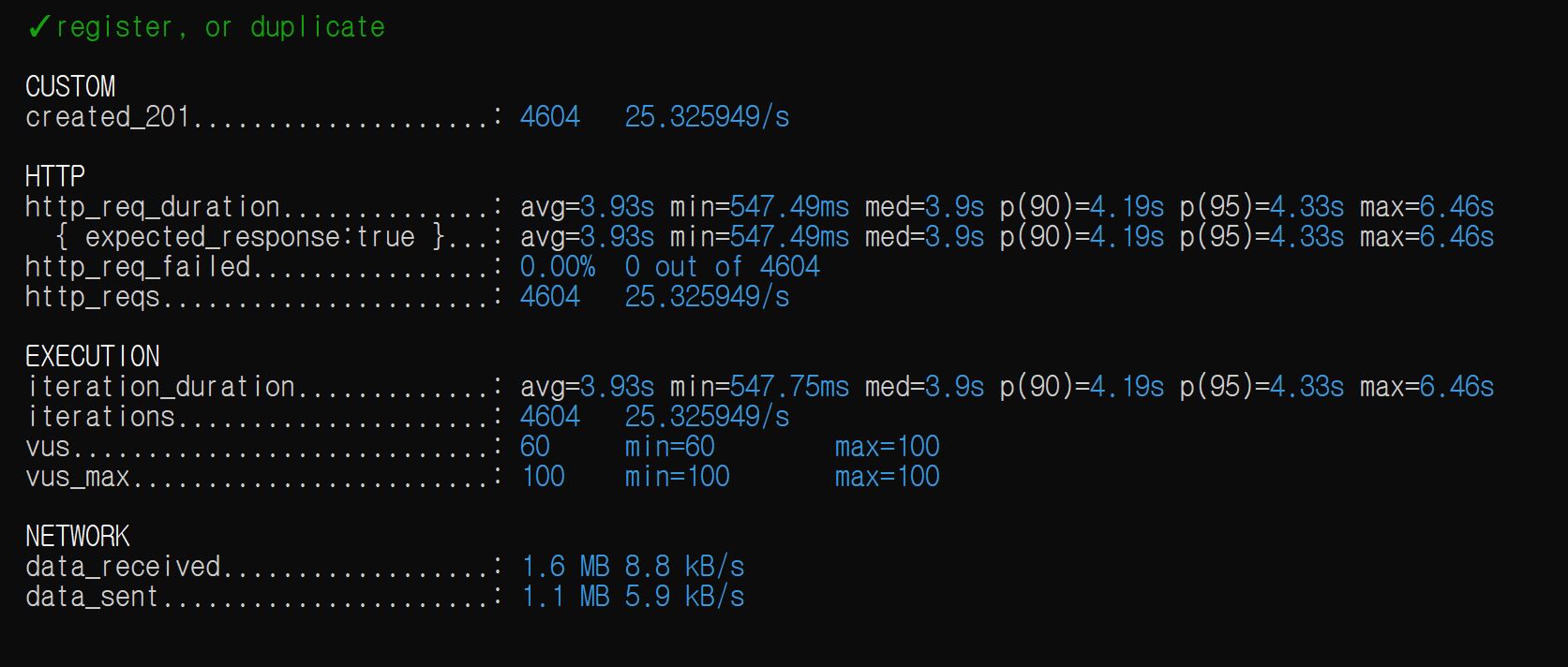
똑같았다. 또한 서버 EC2에서 top으로 CPU 사용량을 보았더니 97까지 치솟았다.
따라서 회원가입 서비스 로직의 암호화 연산이 병목 지점임을 파악했다. gensalt 인자 값을 4로 주어(기본 = 10), CPU 연산을 훨씬 줄여보았고 결과는
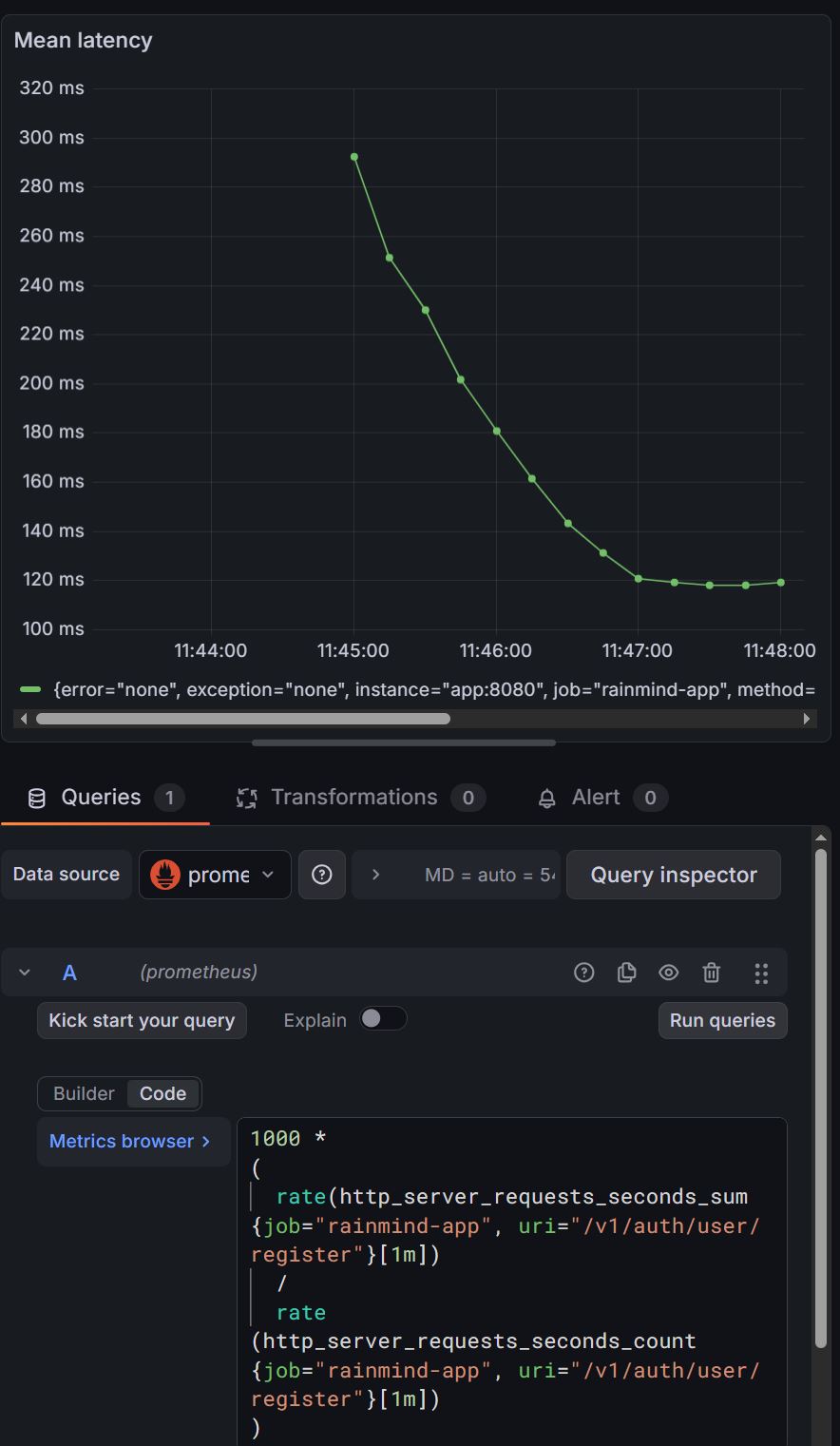
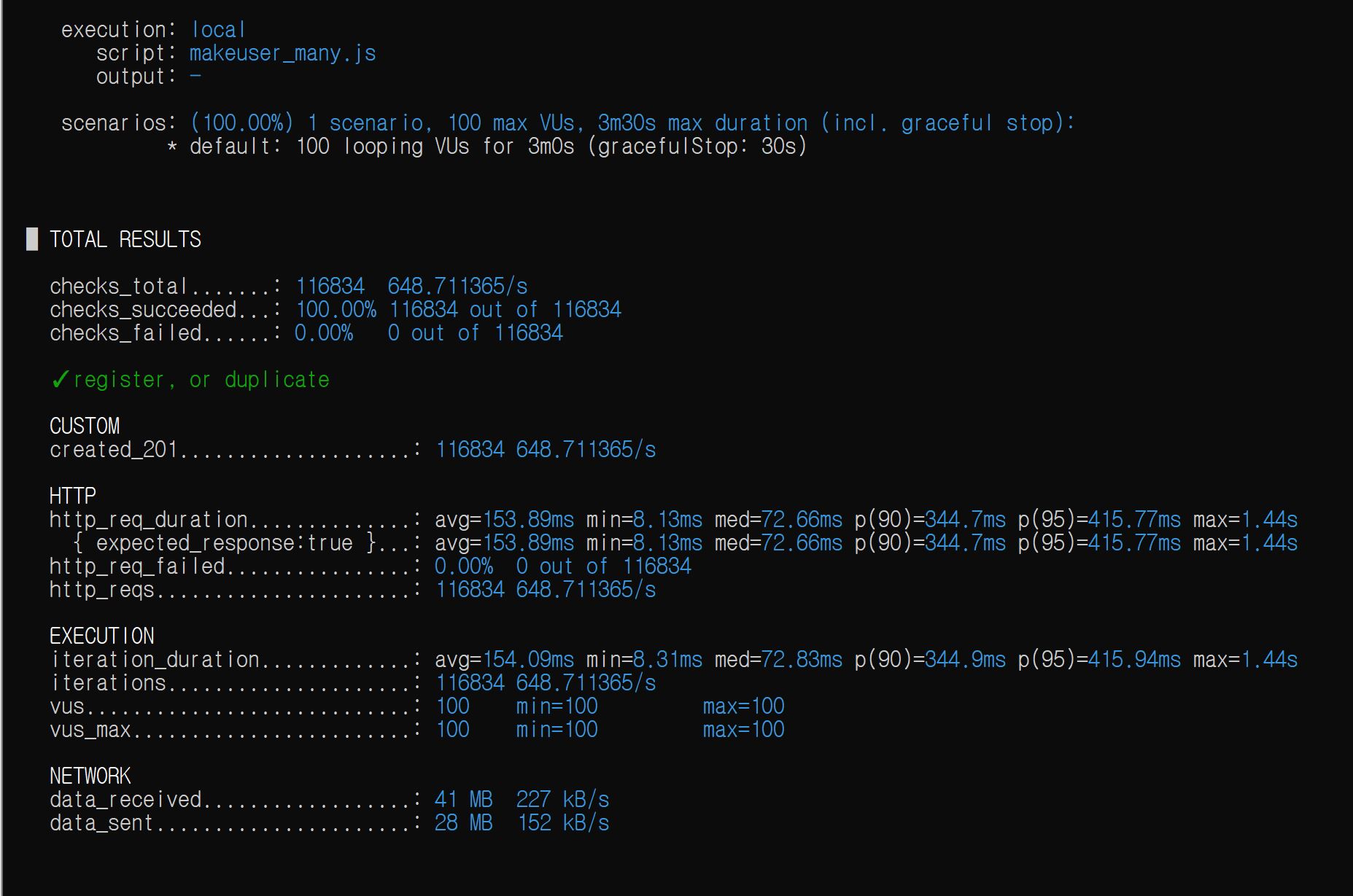
평균 응답시간 및 p(95)를 각각 3.68s, 3.96s -> 153.89ms, 415.77ms로, 거의 9배 가까이 개선할 수 있었다.
그러나, BCrypt 인자를 4로 줄이는 것은, 연산량이 지수적으로 감소하기 때문에 보안적으로 매우 위험하다. 따라서, 하드웨어 자원 업그레이드 혹은 대체 암호화 알고리즘, 적절한 cost factor 조정(서비스 성격에 맞게)이 이루어지는 것이 좋을 것이다.
2) 로그인 기능
현재 로그인 기능은, nickname/password를 받아서 user가 DB에 있고 -> 비밀번호가 일치하면 응답을 반환하는 형식이다.
그러나 같은 IP에서 지속적으로 nickname/password 입력 공격이 온다면 DB 연산 및 BCrypt CPU 연산으로 인해 서버가 심히 느려질 것이다.
따라서, 해당 IP를 redis에 캐싱 후 1분동안 60회가 넘어가는 요청이 오면 해당 IP를 3분동안 차단하여 CPU 자원과 DB 연산을 보호한다.
(전)
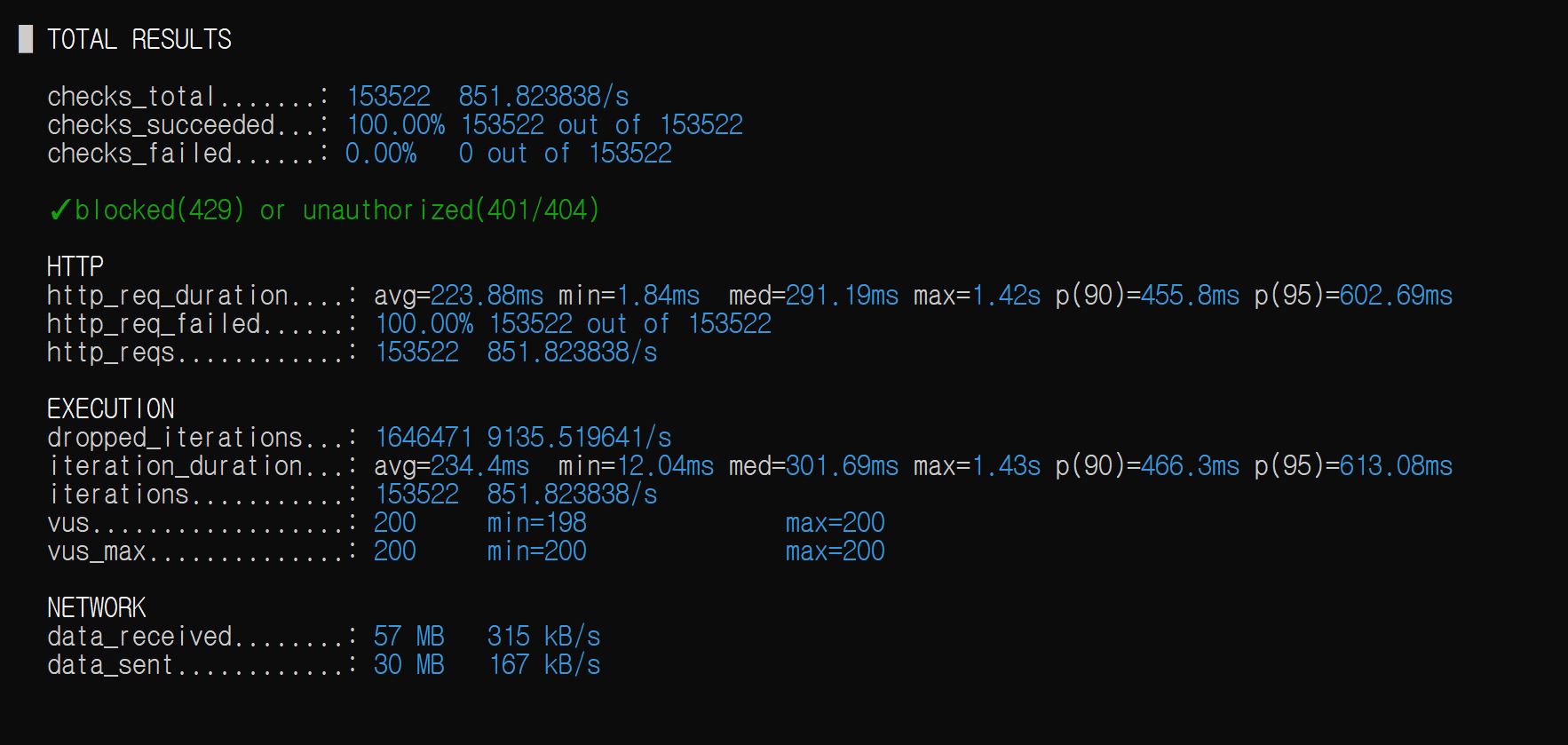
(후)
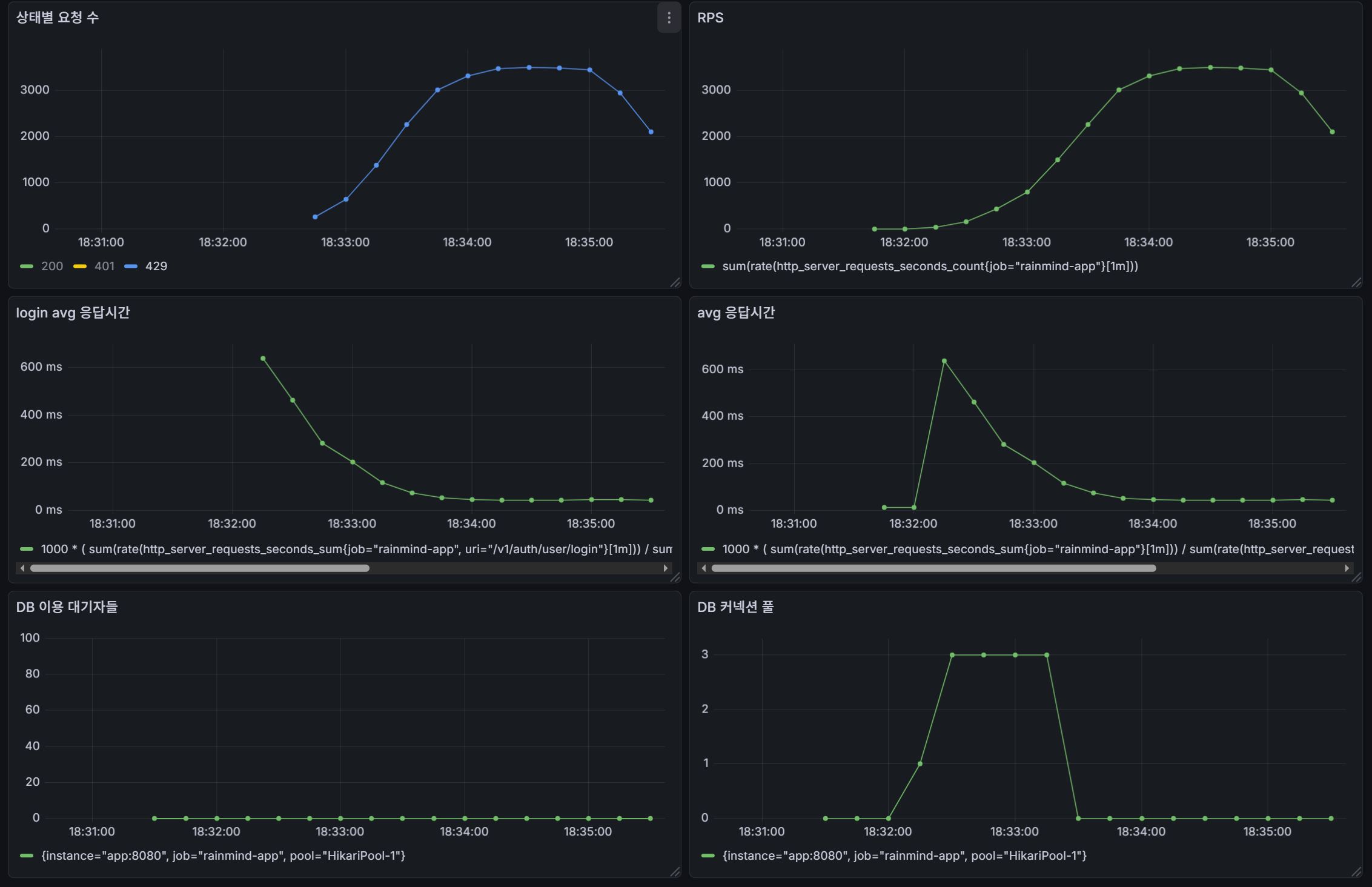
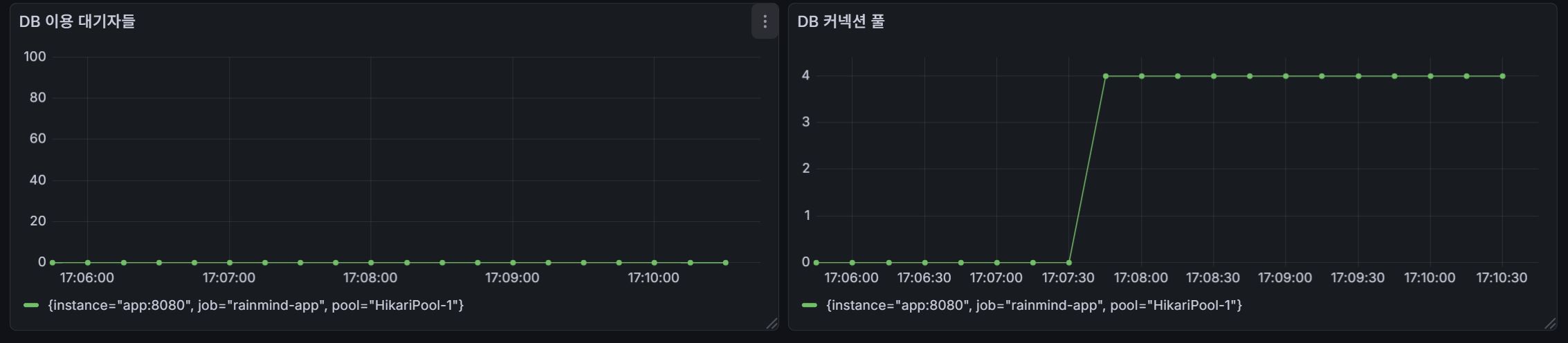
(주요 지표 쿼리)
- max_over_time(hikaricp_connections_pending[1m]) : DB 커넥션 획득하기 위해 대기중인 스레드 수의 max
- max_over_time(hikaricp_connections_active[1m]) : 실제로 DB를 사용중인 커넥션 수
또한 응답시간(avg, p(95)) 또한 약 3배 개선되었음을 알 수 있다.
해당 방법은 같은 IP에서 무작위 nickname / password 대입 공격을 하는 것을 방어하는데 효과적이다.
그러나, 같은 AP(Access Point)를 사용한다면 외부에서 보는 IP는 동일하므로, 정상적인 유저들까지 피해를 입을 수 있다.
본 실험에서는 이를 완화하기 위해 IP를 단순히 짧은 시간(3분) 차단하였지만, 더욱 세부적으로 정책을 도입한다면 특정 IP에서 일정 threshold 이상 요청이 쌓이게 된다면 캡챠와 같은 프로그램을 도입하여 정상적인 사용자를 걸러낸 후, 해당 경우에서만 nickname 과 같은 요청의 정보를 추가적으로 저장하는 것이 좋을 것으로 판단된다. 처음부터 ip:nickname 조합을 모두 저장하면 redis 메모리가 버티지 못할 것이다.
3) 스케줄 생성 기능
현재 어플리케이션의 꽃이자, 가장 중요한 부분인 스케줄 생성 및 redis기능 확인 부분이다.
우선 스케줄 생성 기능부터 로직 다시 점검하였고, 그 결과 유저가 스케줄을 마구잡이로 생성하는 것을 막기 위한 scheduleRepository.findAllByUserId(user.id!!).size 부분이 병목이 될 수 있음을 예상하였다.
왜냐하면 findAllByUserId의 반환형은 List<엔티티> 인데, 이렇게 되면 findAllByUserId시 해당하는 모든 객체들을 힙메모리에 들고오게 되므로, 메모리 사용량 및 응답시간 측면에서 매우 불리하다.
(JPA를 쓰더라도 동일하다. 지연로딩 없이 즉시 힙에 모든 객체를 다 들고온다. 만약 entity 내부에 또다른 entity가 있고, 이를 참조한다면 지연로딩 대상이 될 것이다)
해당 가설을 검증하기 위해, 잠시 인당 스케줄 제한 횟수를 해제하고, DB에 user 200명이 각각 1000개의 스케줄을 만들어놓는다.
이후, findAllByUserId() vs countByUserId()의 성능을 비교한다.
아래처럼 seed_1부터 seed_200까지 200명의 유저들과 각 유저당 1000개의 스케줄을 할당해주고,
JVM의 heap, GC 작동시간, 힙 메모리 사용률을 중점적으로 관찰한다.
< 이전 >
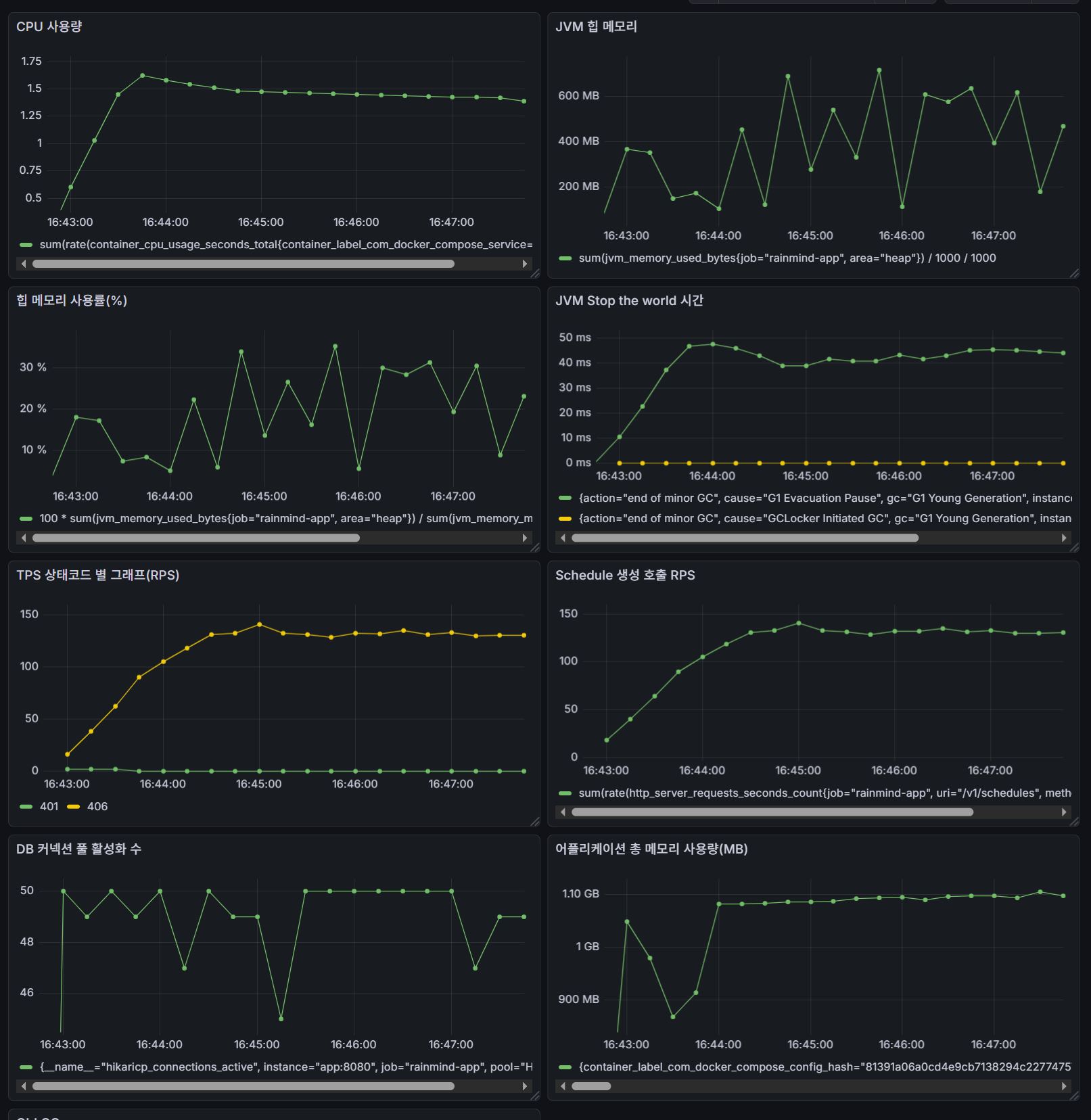
< 이후 : 해당 부분을 countByUserId()로 바꿈 >
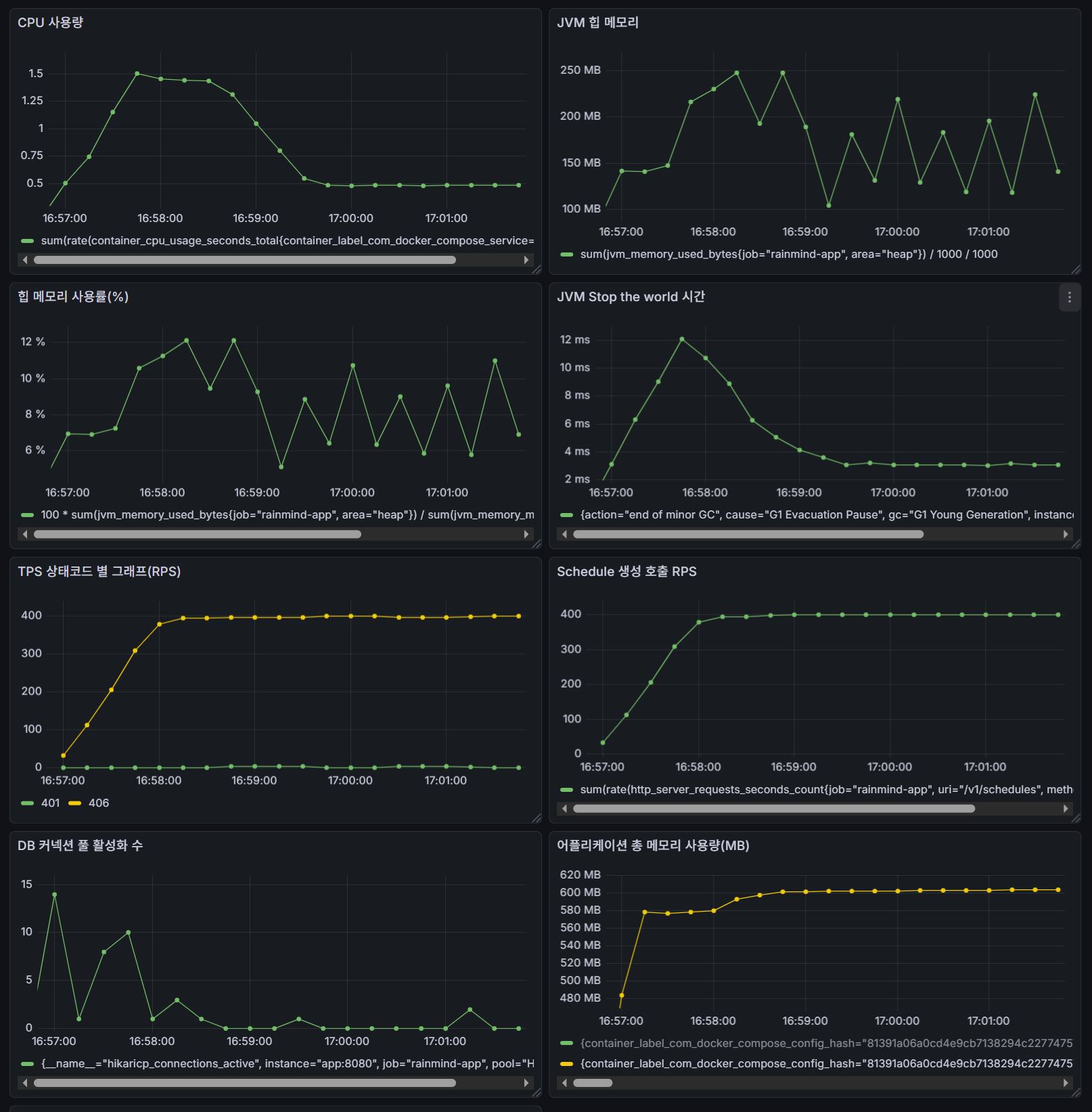
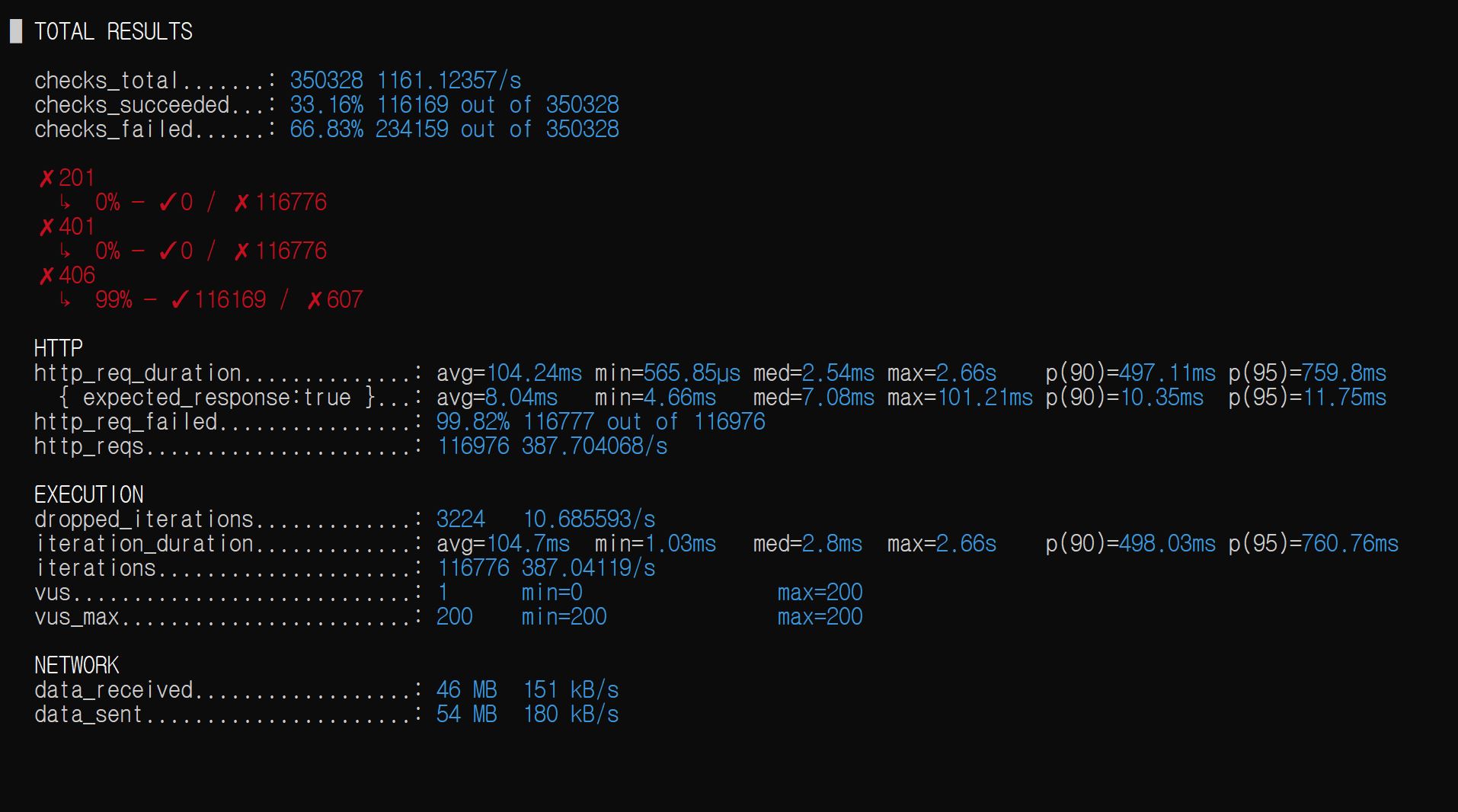
테스트는 의도적으로 fail하도록 설계되었으므로, 테스트 결과는 성공적이며 평균/p(90)/p(95) 응답시간을 포함한 DB 커넥션 풀, JVM 메모리 전반의 수치가 상당히 개선되었음을 확인할 수 있었다.
그러나 이 방식에는 치명적인 약점이 있다. 멀티스레드 환경에서 race condition이 발생할 수 있다.
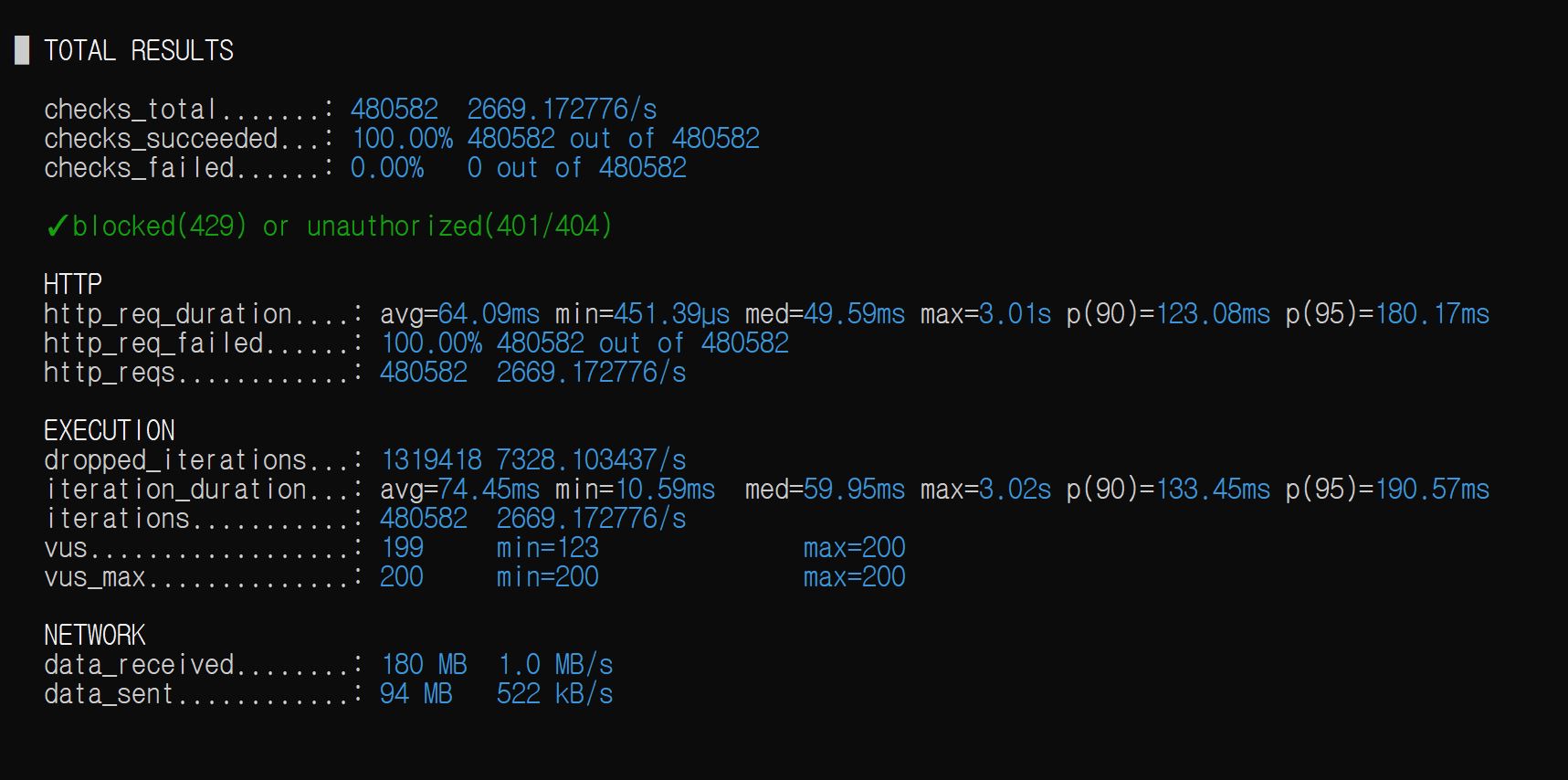
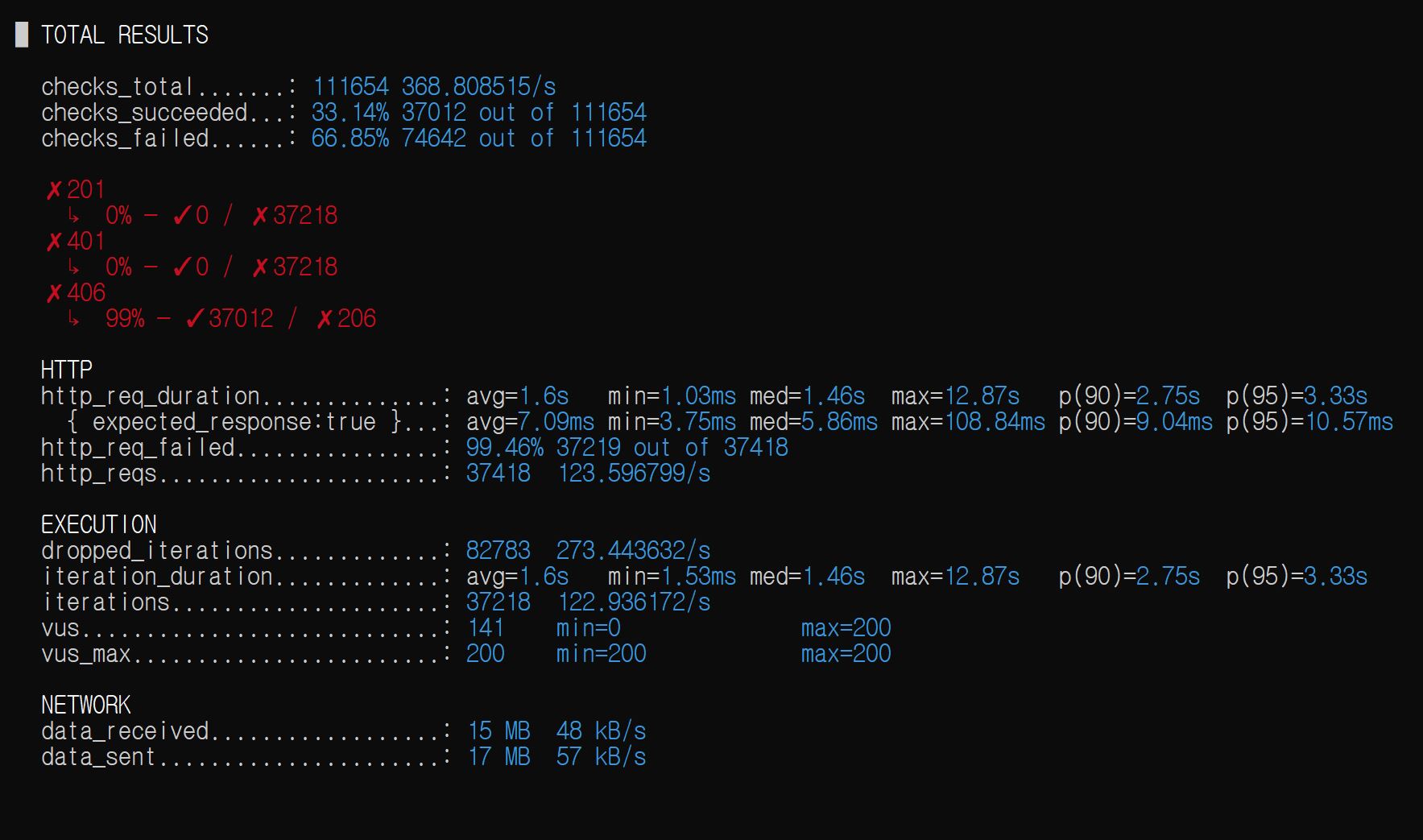
아래 그림은 seed_201 가상의 유저를 만들고, VU = 2000명이 동시에 스케줄을 생성하는 상황을 만들고, 실제 DB에 삽입된 스케줄의 개수를 보여준다.
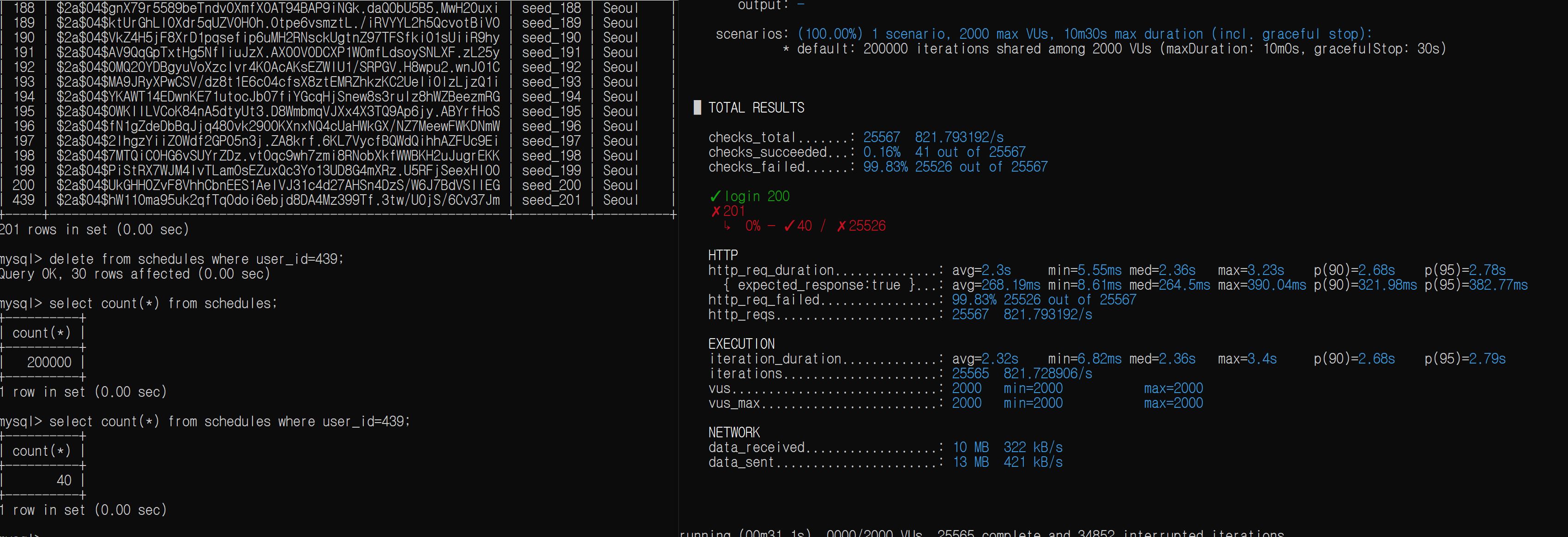
서비스 로직에서는 count >= 30이면 예외 던지기로 막는데, 해당 로직으로는 역부족임을 바로 알 수 있다. 바로 터진다.
일정 제한이 1인당 29개까지인데, 28개인 상황에서 두 개 이상의 스레드가 countByUserId()를 호출한다면 모두 28개를 반환받아 일정을 삽입하는 로직을 수행하기 때문이다.
Spring은 기본적으로 스레드 풀을 사용하는 멀티스레드 환경이기 때문에, 반드시 이를 고려하며 서비스 로직을 설계해야 한다.
이는 이전 포스팅에서 다뤘던 낙관적 락, 비관적 락, 네이티브 쿼리(atomic update)로 해결할 수 있다.
JPA는 참 편리하지만, 복잡한 쿼리를 직접 만들어주는 기능이 없으므로 네이티브 쿼리 작성법에 대해 어느정도 숙지하여야 하는 것이 필수이다. (그래서 프로그래머스 sql을 열심히 풀고 있다)
네이티브 쿼리로 아래처럼 레포지토리 함수를 짠 후,
@Modifying
@Transactional
@Query(value = """INSERT INTO schedules (user_id, title, location_id, start_at, end_at)
SELECT :userId, :title, :locationId, :start_at, :end_at
WHERE (SELECT COUNT(*) FROM schedules WHERE user_id = :userId) <= 29
""")
@Query(value = """SELECT LAST_INSERT_ID()""")
/1.JPG)
/2.JPG)
특히 응답시간이 크게 감소한 것을 확인할 수 있다.
왜 성능이 차이날까?
JDBC는 save 등 DB 반영마다 일일이 쿼리를 날린다. 이 제한을 그나마 완화하는 것이 JPA의 스냅샷(더티 체킹 감지하여 쓰기 지연)이지만, findBy..나 countBy..와 같은 DB 조회 함수들은 항상 DB를 조회하려 한다(다만 findById는 예외, 영속성 컨텍스트의 1차 캐시에 있으면 바로 엔티티 반환). 따라서 바로 DB로의 flush가 발동되어 결국 DB 접근이 발생한다.
또한 기존 로직의 경우, 먼저 조회해서 count를 받고 -> save() 하는 구조였으므로 JDBC의 경우 2번이나 애플리케이션 <-> DB 왕복이 일어난 셈이다. 그러나, 네이티브 쿼리의 경우 단 한번의 쿼리로 전송되므로 해당 왕복 비용이 절감된 것으로 판단된다.
++ 또또 그러나, 해당 쿼리는 race condition을 해결해주지 못할 것으로 판단된다. WHERE 절 안의 SELECT 때문에, 두 개 이상의 스레드가 SELECT를 먼저 실행하게 되고, 모두 통과하여 write를 하게 된다면 여전히 정합성이 깨질 위험이 존재한다. (2026/02/23 수정) race condition은 발생하지 않으나, deadlock에 매우 취약하다(다음 12번 포스팅 참조).
따라서, 대안으로 생각할 수 있는 방법은 총 3가지이다.
- 비관적 락: 레포지토리 함수(User 테이블)에 @Lock(LockModeType.PESSIMISTIC_WRITE)를 걸고 작업한다.
- 낙관적 락: User 테이블에 ‘현재까지 만든 스케줄 수’ 컬럼을 추가 및 @Version 컬럼을 추가한다.
- native query: User 테이블에 ‘현재까지 만든 스케줄 수’ 컬럼을 추가하여, 대략 아래처럼:
@Query(value = """UPDATE users u SET u.schedule_count = u.schedule_count + 1 WHERE u.schedule_count < 30""", nativeQuery = true)와 같은 방식으로 레포지토리 함수를 만든다.
단순함을 생각하면 비관적 락(낙관적 락은 DB 접근이 빈번한 환경에서 재시도 로직 구축 필요하여 비관적 락보다 단순함 측면에서 불리), 아키텍처 구조를 뜯어고친다면 native query가 가장 깔끔한 해결책이 될 것이다.
4) 그외 개선 포인트(시스템 관점)
-
shedlock과 alarm dequeue를 같이 붙인 것 & retryPending()에서, outbox의 PENDING signal을 전부 가져오는것: 사용자가 수십만명대, 일정은 최대 30개(서비스 로직대로)로 가정할 때, 최대 수백만개의 알람을 관리해야 한다. 그러나 확률적으로, 바로 직후 일정에 대해 일정을 만들기보다는 (일반적으로) 며칠 텀을 두고, 그 텀도 사람마다 제각각이며 같은 날짜 안에서 시간도 달라질 것이므로 (실제 서비스 환경으로 들어간다면) redis 내부에 가해지는 부하가 단순 계산한 만큼 심하지는 않을 것이다. 따라서, DB에서 전부 긁어오는것 보다는 페이지네이션 시 사용한 Pageable을 사용하여 10개 또는 100개(분당)씩 긁어오는 방법도 적절하며 DB 접근 시간을 줄일 수 있을 것이다.
-
애초에 DB native query를 사용하지 않고, redis에 count 정보를 임시 저장하는 방안 고려: 그러나 redis 장애 동안 일정 생성 요청이 들어오면 서비스에 구멍이 날 수 있을 것으로 예상되어 패스.
-
Redis를 알람 큐로 계속 가져갈 것이면, payload를 JSON 통째로 넣지 말고 scheduleId, 제목 등 필수적인 요소만 넣어 용량을 줄이고 key를 1개가 아니라 여러개로 분산: payload에 JSON string을 통째로 저장하지 않으면 물론 메모리 사용량이 줄어들 것이다. 이건 충분히 유추할 수 있는 사실이고, 더욱 중요한 것은 여러개의 key로 분산해서 저장하면 같은 데이터라도 redis가 차지하는 메모리가 훨씬 감소할 것이다.
(이어서) Redis ZSET은 내부적으로 skip list와 hash table을 동시에 관리한다(데이터가 일정 개수 이상 많아질 때에). 데이터가 적다면, 이 둘보다 훨씬 가벼운 ziplist를 사용한다. Ziplist는, 하나의 연속된 메모리에 데이터를 붙여 저장하며, skip list는 여러개의 층이 있고 1층부터 확률적으로 배치 여부가 결정된다. 따라서, 최상위 층부터 아래로 내려가며 수학적으로 O(logN)만에 검색이 보장된다.
그러나, 같은 데이터가 복수 존재할 수 있으며, 무엇보다 포인터 오버헤드가 무시 못할 수준이 된다. 그리고, 포인터 형태의 list로 데이터를 저장하므로 삭제/삽입이 자주 일어난다면 fragmentation(단편화)가 반드시 발생한다(내부, 외부 단편화 모두).
따라서, 하나의 key에 모든 알람을 몰아 저장하는 것보다 여러개의 key(사용자 id 등)로 나누어 알람을 저장하는 것이 훨씬 효율적이다.
그러나, 현재 구조의 Redis ZSET의 경우 알람 큐 dequeue 이후 사용자로까지의 도착을 보장하는 로직이 보장되어있지 않아 근본적으로 안전하지 않다. (이에 대한 추가적인 고찰은 아래로)
- ACK 시스템을 가진 RabbitMQ, Kafka 혹은 Redis Stream 사용: 기존 Redis 환경을 활용하여, AOF 설정을 통해 명령어를 디스크에 기록 및 ACK를 받지 못한 메시지 목록을 따로 유지하는 Redis Stream / Exchange(라우터)를 통해 Queue들로의 정교한 라우팅을 제공 및 ACK 시스템을 제공하는 RabbitMQ / 메시지를 특정 topic의 disk에 기록 및 복사하여 consumer에게 전달하는, 대용량 로그 시스템에 적합한 kafka 셋 중에 하나의 도입을 고려 중이다.
이미 Redis를 사용하고 있고, 트래픽이 kafka를 동원해야 할만큼 초당 수천 수만 정도까지는 아닐 것으로 예상되고, 알람을 최대한 일찍 보내는(속도) 것이 중요하여 Redis Stream도 적절한 선택이 될 것이다. 또한 RabbitMQ의 경우, ACK 시스템은 물론 정교한 라우팅과 실패시 로직이 잘 잡혀있는(메시지의 전송을 보장하는데 중점을 두는) RabbitMQ 또한 좋은 선택이 될 것이라 판단된다.