Project : RainMind 개발일지 - 14 [2번째 최적화 수행 기록(수치화)]
이번 최적화는 redis 알람 큐의 설계가 적절한지, dequeue 시간 및 메모리 테스트에 관한 것이다.
초반에, redis를 알람 큐로 쓸때 모든 유저의 날씨 알람을 하나의 key에 전부 저장할지, 아니면 유저별로 key를 할당하는 아키텍처가 적절한지 고민했었다.
Redis ZSet 내부 구현에 따라, 유저별로 key를 할당하는 아키텍처가 메모리 단편화율을 줄일 것이라고 생각했었다. 그래서 초기에는 그렇게 구현했으나, redis <-> 서버 네트워크 RTT가 유저 수에 영향을 받긴 하겠지만 어느정도로 영향이 클지 성능 테스트를 추가로 진행하기로 했다.
-
시나리오:
원래는 유저를 5만명 정도로 만들고, 총 알림 횟수를 50만개로 설정하여 비즈니스 로직에서 제한하는 최대치로 실험을 하려고 했으나, setup 단계에서 5만명의 로그인 정보를 모두 수행하고 이를 VU별로 각각 저장하는 것이 너무 오래걸려서(로그인만 해도 몇분씩 걸렸다..), 유저를 500명으로 한 후, 비즈니스 로직에서 한명당 일정 생성 횟수의 제한을 풀어 10분동안, 총 약 25만개 전후의 알람을 가지고 테스트했다. -
문제 제시: Redis 알람 큐에 많은 양의 알람이 enqueue될때, dequeue scheduler의 작업 수행시간 측정 및 redis 메모리 단편화율 측정
-
해결: 1번 - 유저별로 ZSet key를 두었을때, 2번 - key를 통합 key 하나만 두고 / scheduler가 일정 주기마다 2000개씩 dequeue하는 방식으로 해당 수치들을 측정
Redis의 Active Defrag는 사용하지 않고(OFF) 측정했다.
- 사용 스크립트:
import http from 'k6/http';
import { check, sleep } from 'k6';
import exec from 'k6/execution';
export const options = {
vus: 100,
iterations: 500000,
maxDuration: '2h',
setupTimeout: '5m',
};
const BASE_URL = __ENV.BASE_URL;
const PASSWORD = 'password12345678';
const USER_COUNT = 500;
const PER_USER = 1000;
const LOCATION_ID = 1;
export function setup() {
const tokens = [];
for (let i = 1; i <= USER_COUNT; i++) {
const res = http.post(
`${BASE_URL}/v1/auth/user/login`,
JSON.stringify({ nickname: `seed_${i}`, password: PASSWORD }),
{ headers: { 'Content-Type': 'application/json' }, timeout: '30s' }
);
check(res, { 'login 200': (r) => r.status === 200 });
tokens.push(res.json('token'));
sleep(0.01);
}
return { tokens };
}
export default function (data) {
const iter = exec.scenario.iterationInTest;
const userIdx = iter % USER_COUNT;
const j = iter % PER_USER;
const token = data.tokens[userIdx];
const base = Date.now() + 35 * 60 * 1000;
const res = http.post(
`${BASE_URL}/v1/schedules`,
JSON.stringify({
title: `seed_${userIdx + 1}_bulk_${j}`,
locationId: LOCATION_ID,
startAt: new Date(base).toISOString(),
endAt: new Date(base + 30 * 60 * 1000).toISOString(),
}),
{
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${token}`,
},
timeout: '60s',
}
);
check(res, { '201': (r) => r.status === 201 });
// sleep(0.001);
}
<1번> - 그래프 및 측정 수치 정리
테스트 시작 = 15:50:00
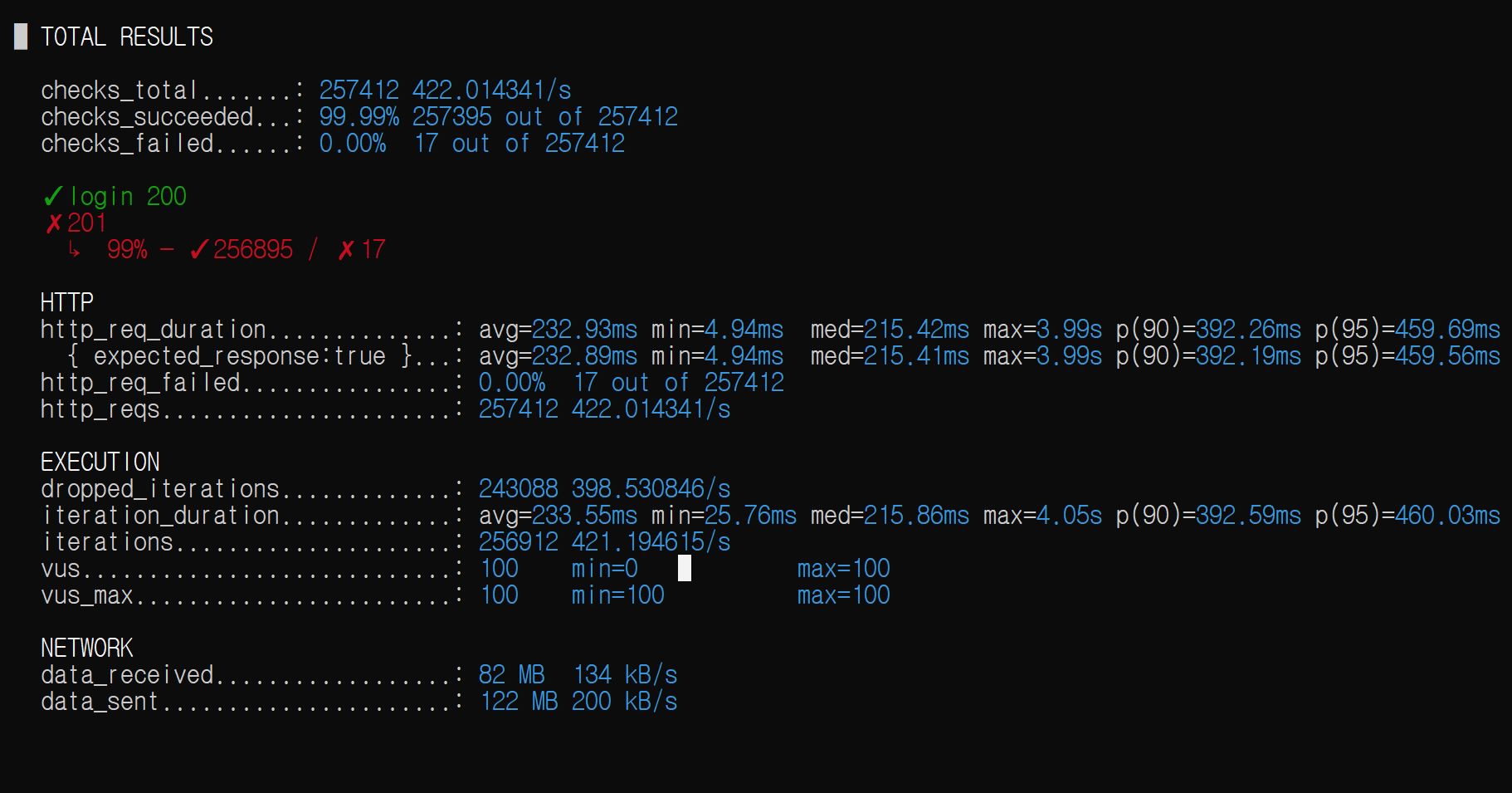
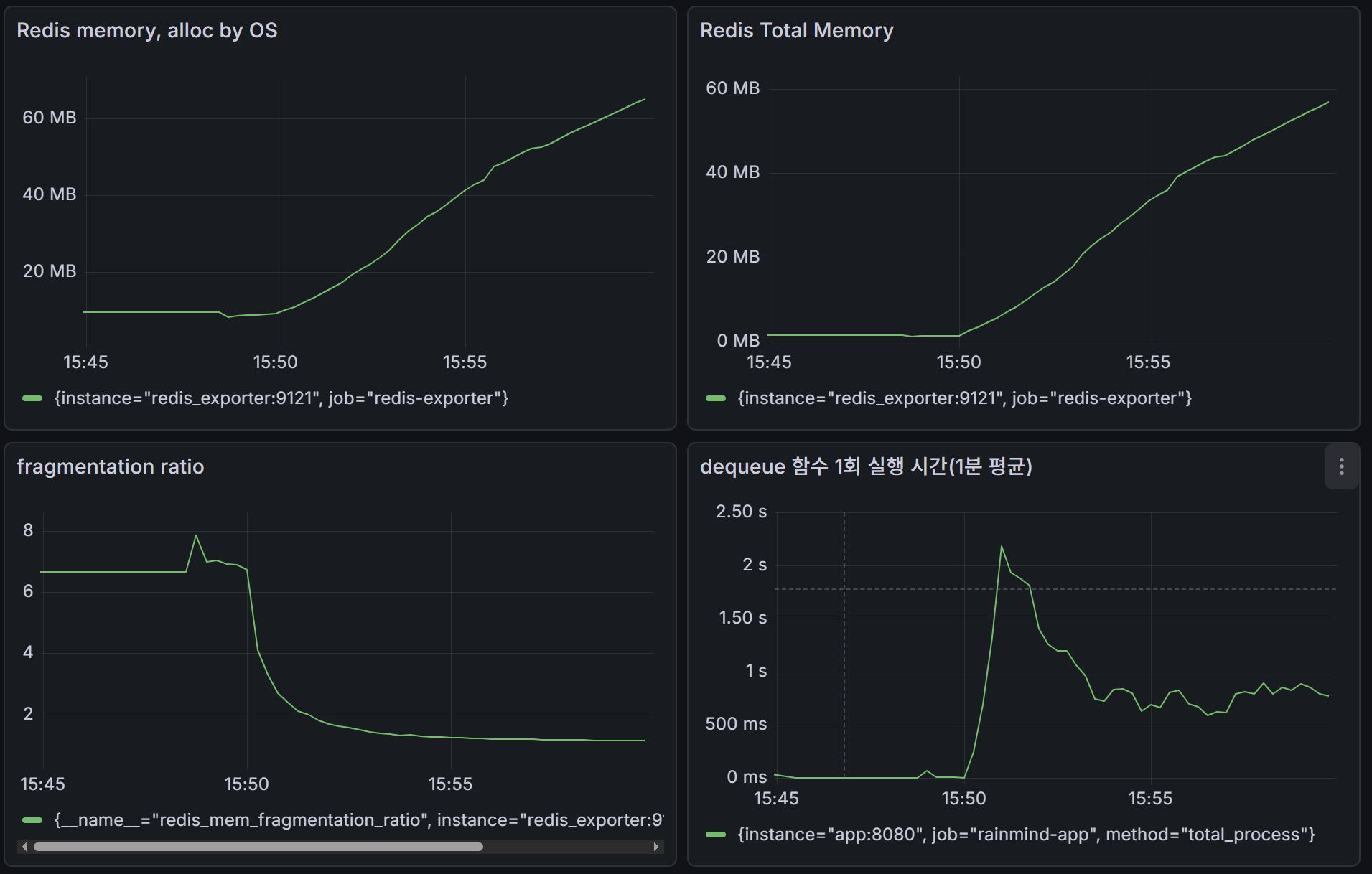
- 측정 지표: Redis Memory Frgmentation Ratio(단편화율), dequeue scheduler 작업 수행시간(=sendAlarm) when 알람을 enqueue만 할때, sendAlarm when 알람이 enqueue/dequeue 둘다 일어날 때
(결과)
| Redis 메모리 단편화율(min) | sendAlarm(only enqueue) | sendAlarm(enq/deq) |
|---|---|---|
| 1.15 | 1.19s | 763.95ms |
메모리 단편화율은 최저값을 쓰기는 했지만, 실제 측정 결과 거의 모든 구간에서 해당 수준을 크게 벗어나지는 않았다.
<2번> - 그래프 및 측정 수치 정리
테스트 시작 = 00:18:00
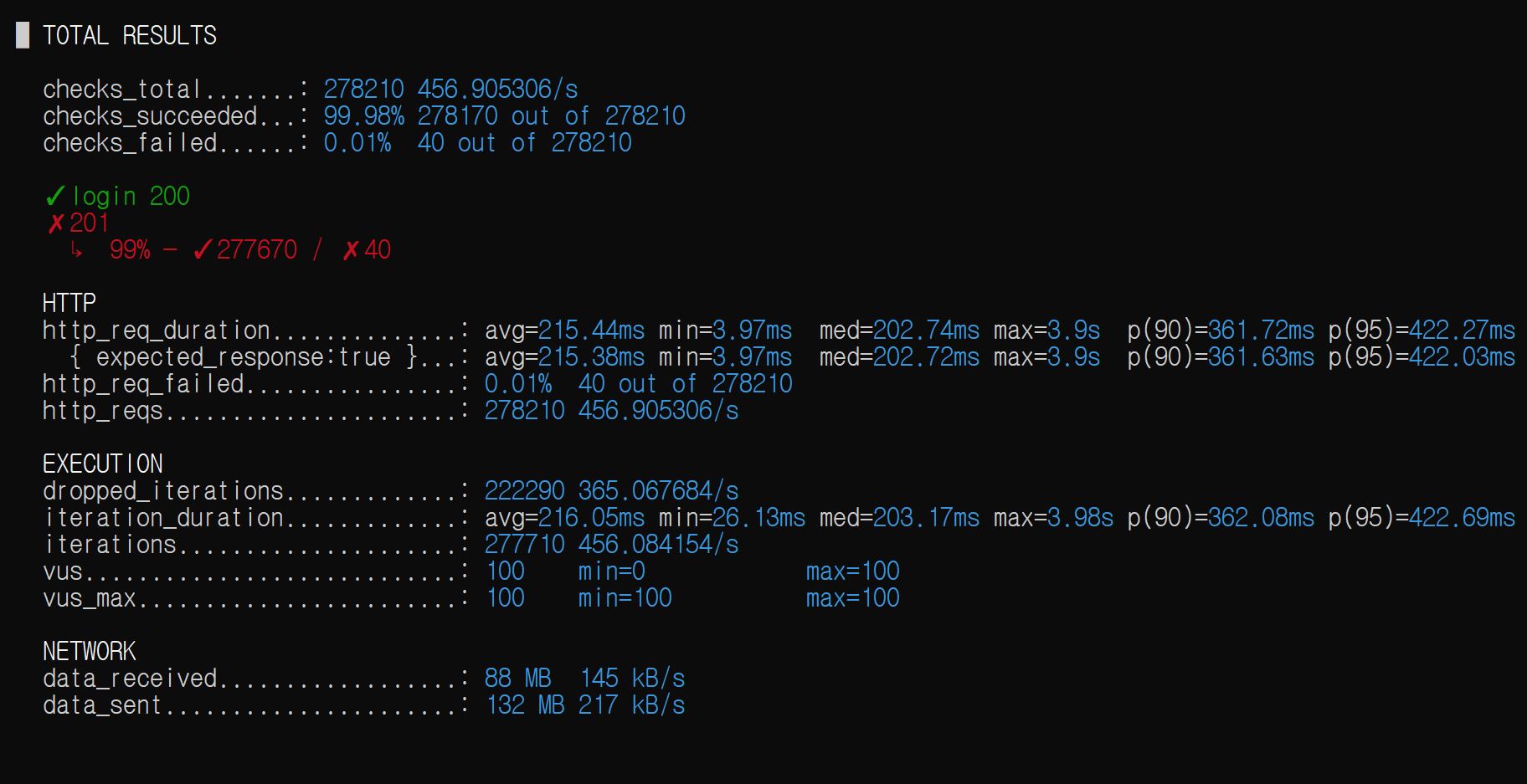
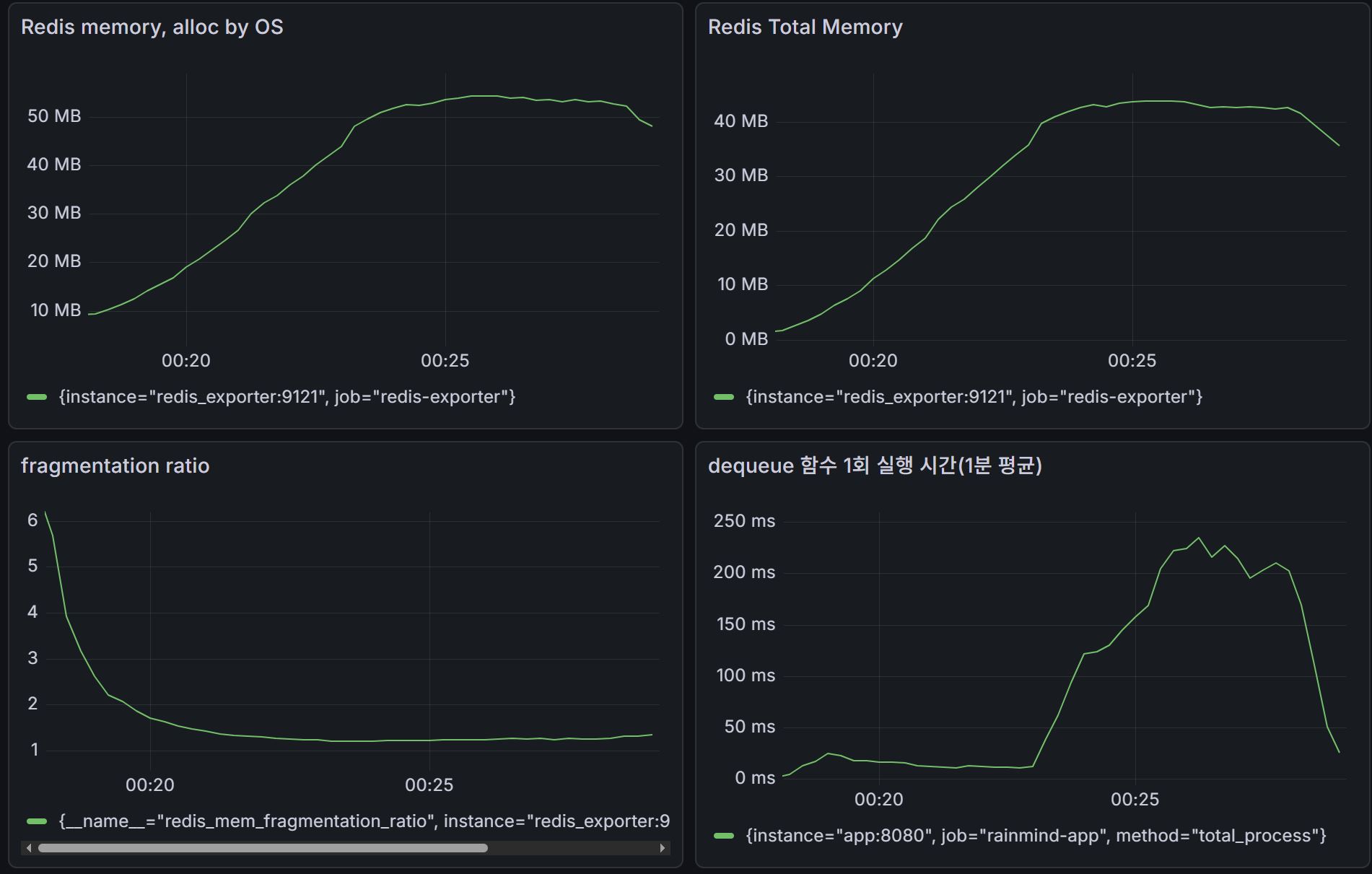
- 측정 지표: Redis Memory Frgmentation Ratio(단편화율), dequeue scheduler 작업 수행시간(=sendAlarm) when 알람을 enqueue만 할때, sendAlarm when 알람이 enqueue/dequeue 둘다 일어날 때
(결과)
| Redis 메모리 단편화율(min) | sendAlarm(only enqueue) | sendAlarm(enq/deq) |
|---|---|---|
| 1.21 | 13.44ms | 169.63ms |
약간의 메모리 단편화율을 희생하여, 1번과 비교했을때 응답시간이 훨씬 안정된 것으로 관찰된다.
테스트 결과 해석:
1) 테스트 시작 직후 sendAlarm(=dequeue) 작업 실행시간이 2s로 확 튄다. 이는 초기 네트워크 연결시, 유저 수에 비례한 요청을 처리하기 위해 네트워크 레이어에서 새로운 소켓을 할당하는 과정에서의 오버헤드가 누적된 것으로 볼 수 있다(+ 요청이 한꺼번에 몰려올 때의 queueing delay 및 네트워크 전송 속도의 slow-start도 요인으로 볼 수 있겠다).
이러한 관점으로 보면, 통합 key 방식을 사용했을때는 유저 수에 비례한 소켓 연결 등의 오버헤드가 없이 batch 방식으로 1번의 접근만이 이루어지기 때문에 초기 enqueue 상황에서도 안정적인 서비스를 유지 가능한 것을 관찰했다.
- “Warmup이 안되어 수치가 왜곡된 것 아닌가?”라는 의문이 들 수 있다. 실제 테스트할때는, 본 스크립트 실행 이전 다른 스크립트들을 충분히 많이 실행하여 예열했고, 로그인과 같은 현재 측정 지표와는 관계없는 과정들은 전부 setup으로 제외하였다. 그리고 단순히 JVM, 네트워크 웜업의 문제였다면 통합 key 방식에서도 동일한 spike가 관찰되어야 하지만, 실제 결과는 그렇지 않았다. 즉 아키텍처 설계의 부하 내구도 차이라는 결론에 도달할 수 있다.
2) 초기 Redis 메모리 단편화율은, 계산 공식이 ratio = (OS가 할당한 메모리) / (Redis 총 메모리) 이므로, 초기에는 enqueue된 알림이 없으므로 분모가 너무 작아 단편화율이 많이 왜곡되어보인다. 실제로 테스트 진행중, 1번과 2번 모두 수치는 빠르게 1점 초반대로 안정화되는 경향을 보였다.
3) 추가적으로, 테스트 종료 후, 모든 알람이 redis에서 dequeue되었을 때 redis의 메모리가 초기 메모리로 완벽하게 돌아오는 것도 확인하였고 memory leak 없이 전 과정을 성공적으로 수행했다.
결론
1) 서비스 배포 직후나 갑작스러운 유저 유입시, 개별 key 방식은 고작 수백명대에서 조차 2s가 넘어가는 치명적인 초기 지연이 발생할 수 있는 반면, 통합 key 방식은 수많은 알람이 enqueue되는 상황에서도 안정적으로 서비스를 제공 가능하다. 즉, 아키텍처 구조 설계가 인프라 레벨의 최적화 옵션보다 훨씬 중요하다는 것을 체감할 수 있었다. 결국 본질은 아키텍처 구조 설계가 얼마나 견고하고 확장 가능한지(가장 완벽한 아키텍처란 존재하지 않지만, 가장 적합한 아키텍처는 존재하는 것 같다)에 대해 고민하는 것이 엔지니어의 역할이라는 것을 알게 되었다.
2) 통합 key 방식은, batch(현재 2000개) 방식으로 단 1번의 RTT를 사용하는 반면, 개별 key 방식은 존재하는 모든 key를 순회한다. 그러므로, 통합 key 방식은 특정 유저의 알람 발송 지연이 생길수 있는 반면 개별 key 방식은 유저별로 redis key를 관리하므로 지연이 거의 발생하지 않는다. 그러나, 앞선 결과처럼 하나의 가치(최대한 빠르게 알림 전송)만을 바라보다가는, 서비스 전체가 마비가 되는(sendAlarm 작업 시간 급증) 즉 더욱 중요한 가치를 놓칠 수도 있다. 따라서, 아키텍처 설계는 항상 trade-off의 연속인만큼, 현재 도메인에서 가장 중요한 가치가 무엇인지, 그리고 지금의 선택이 추후에 어떻게 확장되고 사용될 것인지를 항상 염두에 두고 설계해야 한다는 것을 체감했다.
이로써 우리 서비스의 회원가입/로그인/스케줄 생성(DB)/Redis queue 메모리 및 작업시간 관리까지, 핵심 부분의 성능 최적화를 1차적으로 완료하였다. 다음 단계로는, CI/CD 및 실제 배포 사이클에 대해 공부하고 수행해보고자 한다.