SNUXI 개발일지 - 7 [최적화 수행 기록(수치화) - 2nd : 인터페이스 변경 / 레포지토리 함수 호출 최적화를 통한 쿼리 횟수 및 응답 시간 개선]
SNUXI 서비스에서, 페이지네이션 SQL 로그 관찰 및 API 성능 개선에 사용한 스크립트와 PromQL 쿼리, 데이터 수치화를 기록한다.
페이지네이션 API 쿼리 횟수 추적 및 개선
(1) 목표 RPS 계산: 유저당 최악의 경우 50회씩 페이지네이션 수행한다고 가정할 때, 총 API 호출수 = 유저 수(2만명) * 50회(유저당) = 100만회
100만회의 API 호출이 15분(피크타임) 동안 일어난다고 가정 -> 1000000 / 15 / 60 = 1111.11…..
따라서 일반적인 유저의 상황을 고려할 때, 목표치 RPS의 기준값을 1000으로 근사하여 성능 테스트를 수행한다.
-
문제 제시 페이지네이션 API의 호출 부하 테스트 결과가 목표 RPS에 도달하지 못하여, 서비스 로직의 쿼리 개선 필요
-
사용 스크립트 : 페이지네이션 방식 선택에 사용했던 이전 스크립트와 같은 시나리오 사용(스크립트 링크 : 스크립트 & 시나리오)
-
해결 : 페이지네이션 서비스 로직의 repository 함수 호출 검토 결과,
(1) Page -> Slice 인터페이스 변경을 통한 불필요한 COUNT(*) 쿼리 감소 효과 개선 기대
(2) 함수 초반의 참여정보 존재유무 파악 로직과, 함수 후반의 DTO 반환 시 참여정보 fetch 로직을 하나로 합쳐서 -> 함수 초반부터 fetch + associate { } 문법을 이용하여, 해당 채팅방의 참여정보에 input user id가 존재하는지 검증 : 불필요한 함수 호출 통합하여 쿼리 감소 효과 개선 기대
두 가지 개선사항이 발견됨. 따라서 application.yaml에서 show_sql 옵션을 켜서 실제 함수 호출 시 생성되는 쿼리를 관찰함.
- 사용 쿼리(해당 지표들은 서버의 한계 상황임을 보여주기 위함)
- hikaricp_connections_active{pool=”HikariPool-1”} / hikaricp_connections_max{pool=”HikariPool-1”} DB 커넥션 풀 점유율
- rate(hikaricp_connections_usage_seconds_sum[1m]) * 1000 초당 DB 커넥션 풀 점유시간
-
sum(rate(container_cpu_usage_seconds_total{name=”snuxi-local-mysql”}[1m])) * 100 MySQL CPU rate(%)
- 측정 지표
- 응답 시간(avg, p(90), p(95)) 및 RPS
개선 전 테스트 결과
-
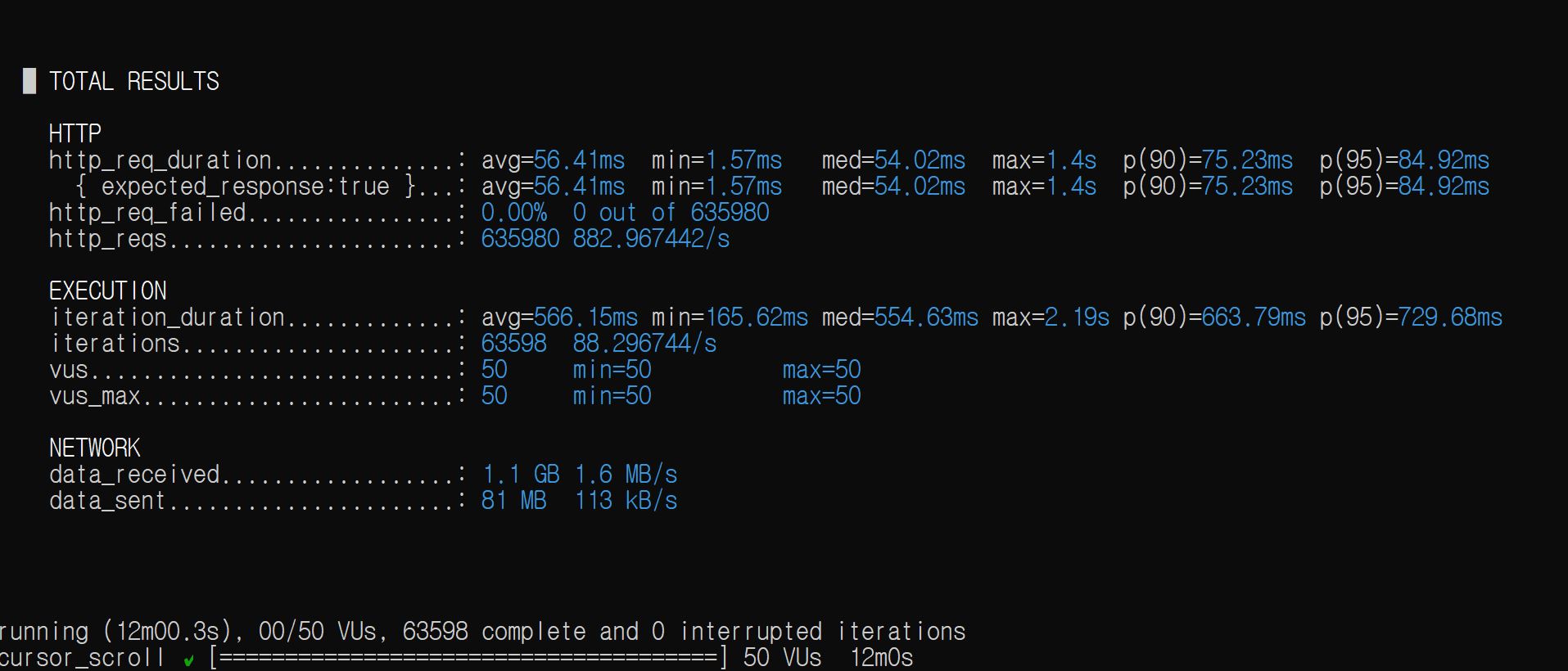
k6 콘솔:
-
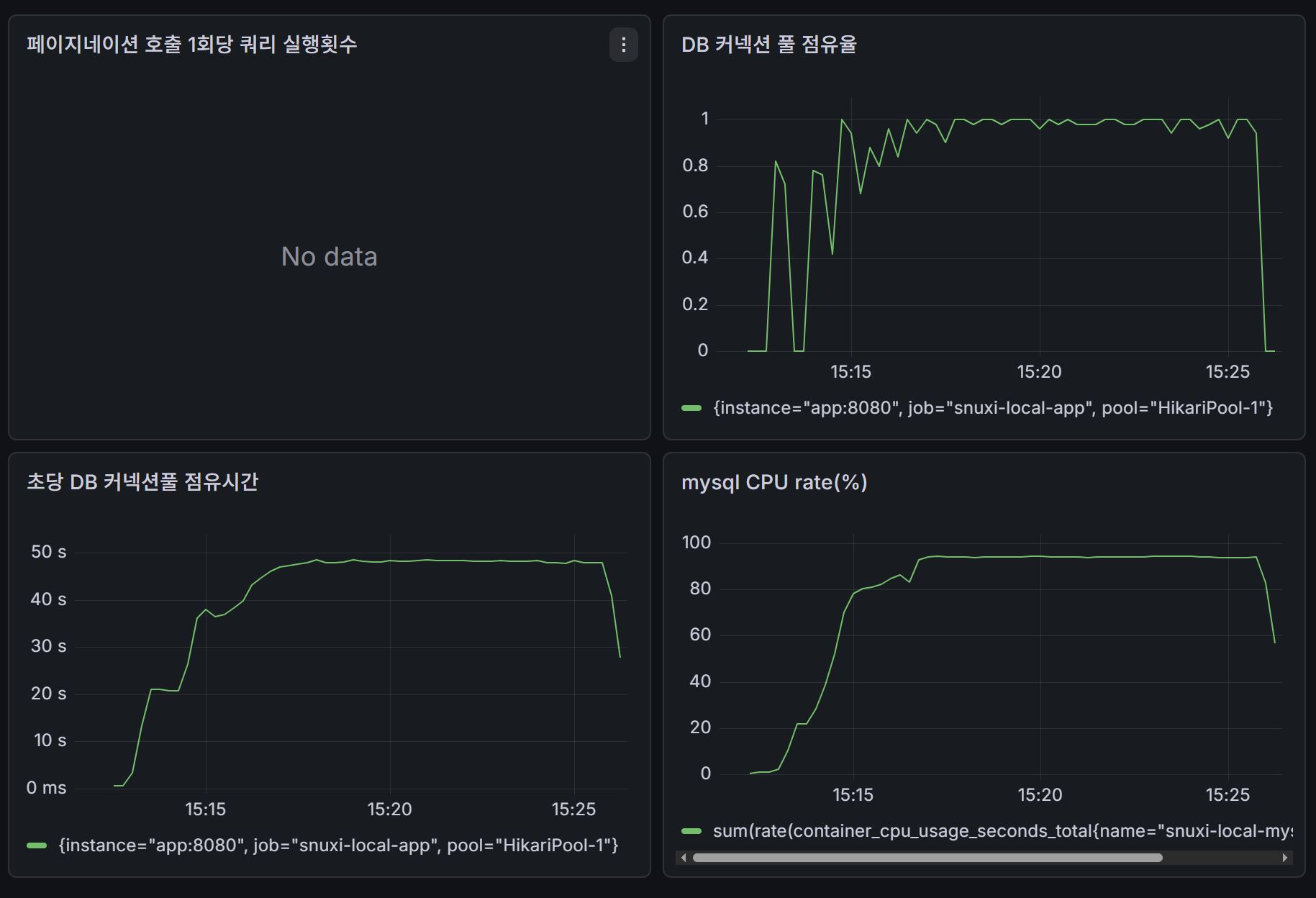
Grafana 그래프:
-
Hibernate 쿼리 실행 확인:
.JPG)
쿼리 실행 횟수는 총 5번이다.
- 표로 정리
| avg | p(90) | p(95) | RPS |
|---|---|---|---|
| 56.41ms | 75.23ms | 84.92ms | 882.97 |
개선 후 테스트 결과
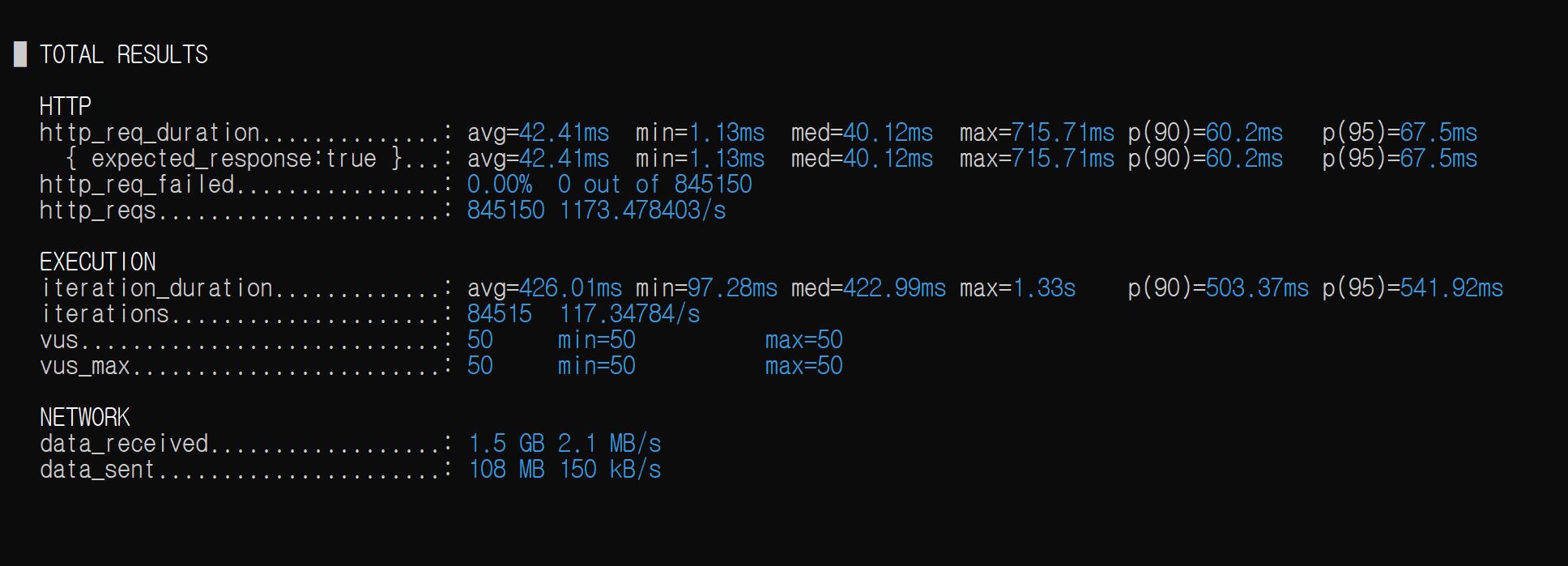
-
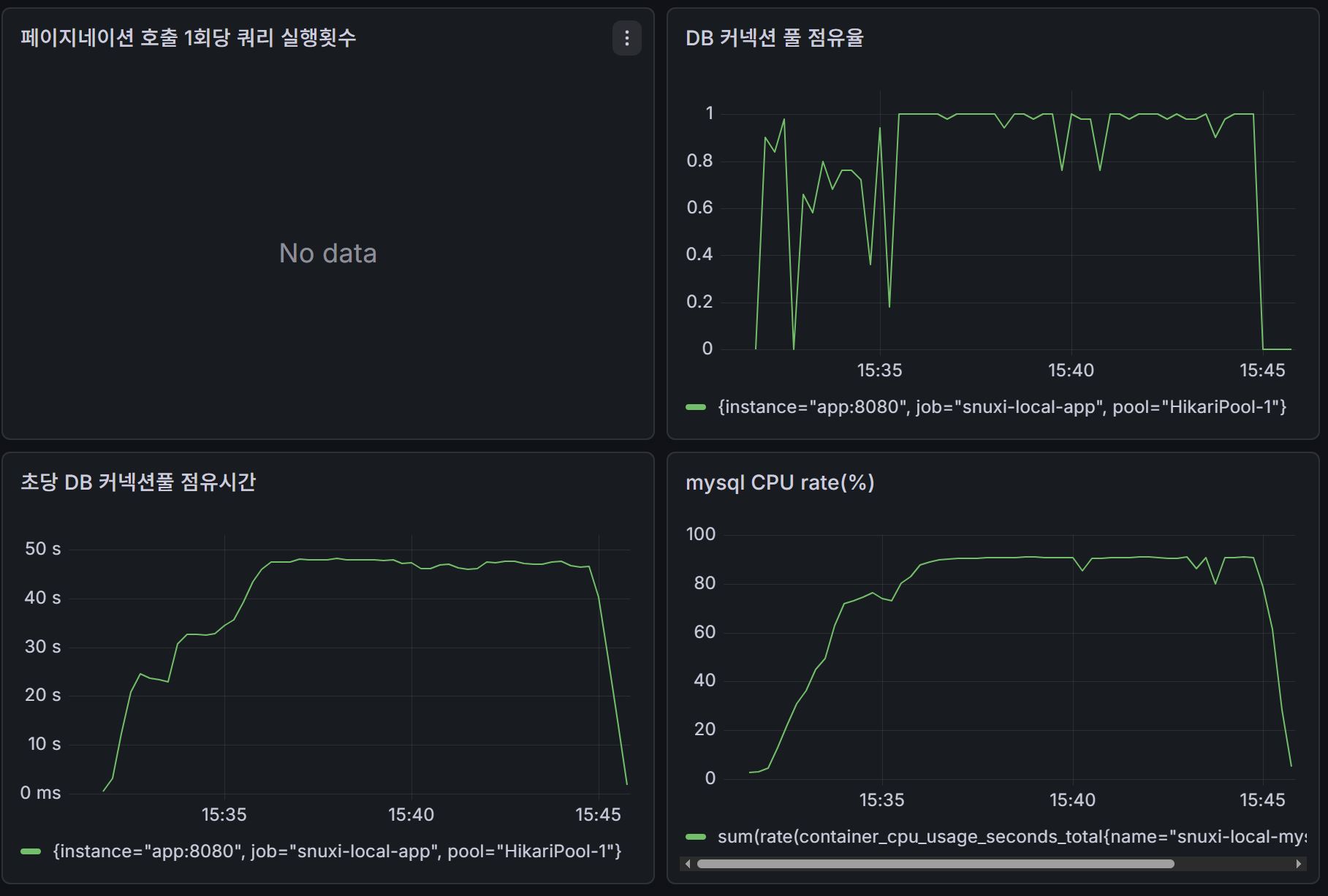
Grafana 그래프:
-
Hibernate 쿼리 실행 확인:
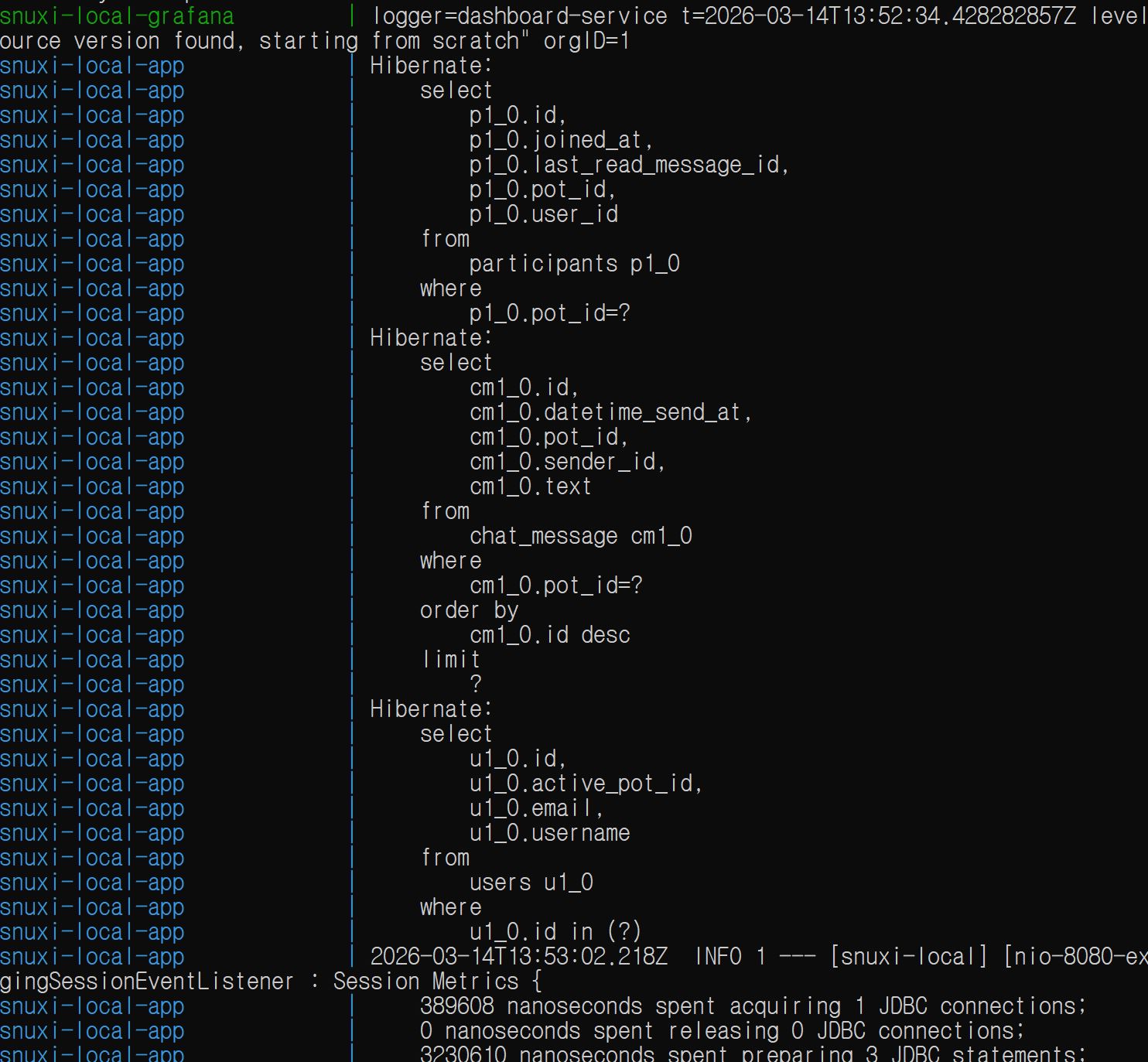
쿼리 실행 횟수는 총 3번이다.
- 표로 정리
| avg | p(90) | p(95) | RPS |
|---|---|---|---|
| 42.41ms | 60.2ms | 67.5ms | 1173.48 |
결과 분석
1) 두 경우 모두, Grafana 그래프에서 CPU 사용률이 100% 및 DB 커넥션 풀 점유량이 1에 근접했다. 즉 현재 시나리오에서 서버의 한계에 도달했다는 것을 의미한다.
2) 쿼리 실행 횟수가 5회 -> 3회로 개선되었다.
이는 초반에 예측한 Page -> Slice 인터페이스 변경으로 의한 COUNT(*) 쿼리 제거 및 레포지토리 함수 호출 통합에 의한 불필요 SELECT … LIMIT 1 쿼리가 제거된다는 가설이 옳음을 보여준다.
-
Why? Page 인터페이스는, 정의상 전체 행 개수 정보를 필요로 하므로 추가 쿼리가 발생하고, Slice 인터페이스는 LIMIT n + 1 즉 미리 다음 데이터까지 조회하여 그것이 존재하는지 여부로 간단하게 무한스크롤 지속 여부를 알 수 있기 때문이다.
-
이전 게시글 중에 Page interface / PageRequest class / Pageable interface의 구현을 살펴보고 상속 관계를 정리해본 게시글이 있는데(
), 이렇게 최적화에 사용이 되는구나 라는 것을 알게 되었다.
이에 따라 평균 응답시간/p(90)/p(95) 모두 대략 20~30% 정도 개선되었다. 이는 목표 RPS 달성 뿐만 아니라, 서버 자원의 사용을 효율적으로 개선함으로써 평균 시나리오보다 더 높은 트래픽 또한 견딜 수 있는 시스템의 견고함이 향상되었다고 볼 수 있다.